Inleiding
De belangstelling voor conventionele vormen van tweaken, zoals het overklokken van processors en videokaarten in desktopcomputers, is de laatste jaren tanende. Door de goede prestaties van de moderne cpu's en gpu's levert overklokken nauwelijks nog merkbare snelheidswinst op. Veel tweakers laten hun hardware daarom ongemoeid of houden het bij een eenvoudige overklok die geen concessies doet aan bijvoorbeeld de geluidsproductie van een systeem. De aandacht is verlegd naar zaken die er nog wel toe doen, zoals het bevrijden van smartphones uit het keurslijf van de fabrikant. Tweaken is immers leuk maar het moet wel nut hebben.
Een ontwikkeling die niet onopgemerkt is gebleven in de Pricewatch en op het forum is de gegroeide belangstelling voor interne en externe opslag. Solid state drives en nas-apparaten behoren al tijden tot de meest gezochte Core-producten. Voor systemen die zijn aangewezen op mechanische opslag is een ssd veruit de beste prestatieverbeterende upgrade. De opslagcapaciteit die ssd's niet bieden, is binnen handbereik met de aanschaf van een nas. Die voorziet bovendien beter in de behoefte om de grootste dataverbruikers van dit moment - downloads van films en series - te delen met mediaspelers. Ook kunnen ze gebruikt worden voor het maken van centrale backups. De populariteit van ssd's en nas-servers maakt duidelijk dat de tweaker behoefte heeft aan veel opslagcapaciteit, en geeft om snelle én veilige opslag van zijn data.
Veel gebruikers zullen genoeg hebben aan de opslagcapaciteit van vier tot zes harde schijven in raid 5, zolang er geen bijzonder goede prestaties nodig zijn. Steeds meer mensen ervaren de matige prestaties van filesharing over gigabit-ethernet echter als een beperking. Terwijl pci, usb, serial ata en andere interfaces in de afgelopen jaren forse snelheidsupgrades hebben ondergaan blijft de bandbreedte van betaalbare netwerkinterfaces voor thuis al bijna een decennium steken op een gigabit per seconde. In de praktijk levert filesharing over smb tussen Windows-machines zelden een doorvoer van meer dan 70MBps en vaak zelfs aanzienlijk minder, terwijl een enkele harde schijf onder optimale omstandigheden al meer bandbreedte kan leveren dan een gigabit-ethernetverbinding.
Als het niet de prestaties van een kant-en-klare nas-server zijn die een beperking vormen, dan is het wel de limiet van vier tot zes schijven in betaalbare nas-servers. Steeds vaker wordt er een opslagcapaciteit van meer dan 10TB verlangd. Zelfbouw wordt dus interessanter naarmate de behoefte aan opslagcapaciteit groter is.
Tweakers die veel opslagcapaciteit nodig hebben en verlost willen worden van de bottleneck van filesharing over gigabit-ethernet, vinden op de consumentenmarkt weinig toepasselijke oplossingen. Enterprise-opslagsystemen dragen prijskaartjes van vele tienduizenden euro's en vallen vanzelfsprekend niet binnen het budget van thuisgebruikers. Dankzij bijdragen van grote serverfabrikanten aan de opensource-community en de beschikbaarheid van aantrekkelijk geprijsde, gebruikte enterprise-hardware op eBay kan elke hobbyist nu echter voor redelijke prijzen hardware en software met enterprise-features en -prestaties in huis halen.
Een goed voorbeeld van een opensource enterprise-oplossing voor netwerkopslag is de combinatie van het zfs-bestandssysteem en het Comstar-framework van Sun. Dankzij de opensource-affiniteit van de voormalige Sun-bestuurders heeft elke thuisgebruiker hiermee de beschikking over een van de geavanceerdste bestandssystemen van dit moment; het is een koud kunstje om een systeem om te bouwen tot een scsi-target waarmee serveropslagruimte als een lokale harde schijf benaderd kan worden.
")
Dit artikel is het eerste uit een serie van twee waarin we dieper zullen ingaan op de mogelijkheden van zfs en de prestaties van network attached storage (nas) en storage area networks (san) op basis van zfs en fibrechannel, infiniband en gigabit-ethernet. De artikelen zijn gericht op tweakers die niet te beroerd zijn om hardware van eBay te plukken, die de command-line niet schuwen en die een bovengemiddelde honger hebben naar opslagcapaciteit en prestaties.
In dit eerste deel bespreken we de mogelijkheden van zfs, geven we advies over de samenstelling van een zfs-server en onderzoeken we de prestaties. We kijken onder andere naar de invloed van diverse tunables, raid-levels, het aantal disks, caching, compressie en deduplicatie. In een vervolgartikel zullen we verschillende soorten netwerkconnectiviteit vergelijken en het verschil tussen network attached storage en een storage area netwerk bespreken. Met behulp van deze informatie zul je zelf de beste hardware voor een zfs-opslagserver kunnen uitzoeken.
Zettabyte File System
Het Zettabyte File System, beter bekend als zfs, werd aangekondigd in 2004 en wordt sinds 2006 met het Solaris-besturingssysteem meegeleverd. Zfs onderscheidt zich van andere bestandssystemen doordat het ook de functionaliteit van een volume-manager biedt. Andere bijzondere features zijn de goede bescherming tegen datacorruptie, de ondersteuning van snapshots, het gebruik van een copy-on-write-model, de continue integriteitscontroles, de automatische reparatie van gegevensfouten en de ondersteuning voor zeer grote volumes.
Zfs is beschikbaar voor de besturingssystemen Solaris, OpenSolaris, OpenIndiana, FreeBSD en een aantal andere van BSD afgeleide besturingssystemen, zoals FreeNAS en NetBSD. Zfs is ook beschikbaar als bestandssysteem in userspace voor Linux en er wordt gewerkt aan een native Linux-versie.
Storage pools
Conventionele bestandssystemen beslaan een enkele disk en hebben de hulp van een volumemanager of een raidcontroller nodig om meer fysieke drives te combineren tot een groot logisch volume, eventueel met redundantie. Zfs combineert de functionaliteit van bestandssysteem en volumemanager. Zfs-bestandssystemen worden gebouwd in zogenaamde zpools, die weer uit een of meer vdev's bestaan. Vdev's - virtual devices - zijn gebaseerd op fysieke block devices zoals bestanden, partities of complete drives, waarbij de laatsten de voorkeur genieten. De block devices in een vdev kunnen worden geconfigureerd in een stripe- (raid 0) of mirror-set (raid 1), of met een raid-level met enkel- of meervoudige pariteit (raid-z1, raid-z2 en raid-z3). Een combinatie van striping en mirroring of een raid-z is ook mogelijk door meerdere mirrors of raid-z-vdev's aan een zpool toe te voegen.

De capaciteit van vdev's kan niet worden uitgebreid, maar het is wel mogelijk om extra vdev's aan een zpool toe te voegen. Om een zpool te beschermen tegen uitval van drives moeten de onderliggende vdev's redundant gemaakt worden met mirroring of parity.
Zfs maakt gebruik van dynamische striping. Als er extra drives aan een pool worden toegevoegd, wordt de breedte van de stripe automatisch vergroot om de nieuwe disks mee te laten doen in de stripe. De blokgrootte is variabel tot een maximum van 128KB.
Data-integriteit
Zfs is vanaf de basis gebouwd om een hoge data-integriteit te bieden. De integriteit van het bestandssysteem wordt gewaarborgd door in de gehele bestandssysteemboom checksums te gebruiken. Van elk datablok wordt een checksum berekend, en die wordt opgeslagen in de pointer naar het datablok. Ook van de blokpointers wordt weer een checksum gemaakt, die wordt opgeslagen bij de pointer naar deze blokpointer. Checksums worden op alle niveaus in de hiërarchie van het bestandssysteem gemaakt: zelfs de root node heeft een checksum.
Bij het raadplegen van een blok wordt de checksum van de ingelezen data opnieuw berekend en vergeleken met de opgeslagen checksum bij de blokpointer. Als de checksums met elkaar overeenkomen wordt de data doorgegeven aan het proces dat de aanvraag deed. Bij een verschil tussen de twee waardes zal zfs de data kunnen repareren als de storage pool redundantie biedt. Op een storage pool met een enkele disk kan redundancy verkregen worden door zfs meerdere kopieën op dezelfde disk te laten maken. Uiteraard beschermt dat niet tegen uitval van de disk.
Dankzij de checksums en self-healing is zfs goed beschermd tegen zogeheten silent data corruption, waarbij verschijnselen zoals bit rot, straling, stroompieken en loszittende kabels ervoor zorgen dat bitjes er op de disk anders bijliggen dan de bedoeling is. Normaal gesproken zou de gebruiker hier nooit weet van hebben; een gewone raid-controller beschermt niet tegen dergelijke fouten omdat die de gegevens bij het inlezen niet valideert.
Om gebruik te maken van de self-healing-functies van zfs moet het systeem wel controle over de redundancy van de data hebben. Het is daarom aan te raden om host bus adapters zonder raid-functionaliteit te gebruiken, of om de drives die op een raid-controller zijn aangesloten als losse logical units te configureren.
De gebruiker kan desgewenst met de scrub-tool een controle van, en eventueel reparaties aan het bestandssysteem uitvoeren. In tegenstelling tot de fsck-reparatietool op andere Unix- en Linux-besturingssystemen controleert scrub niet alleen metadata, maar ook de data zelf. Bovendien hoeft het bestandssysteem hiervoor niet offline gehaald te worden.
Copy-on-write, snapshots en clones
Zfs maakt gebruik van een copy-on-write-transactiemodel. Gegevens worden bij een wijziging nooit op dezelfde plek overschreven. In plaats daarvan wordt de wijziging naar een nieuw blok geschreven en worden de referenties naar het oude blok aangepast. Een vergelijkbare strategie wordt toegepast in solid state drives om de overhead van wijzigingen in flashgeheugenblokken te minimaliseren. Bij een storage pool van harde schijven heeft de copy-on-write-strategie als voordeel dat random schrijf-i/o feitelijk wordt vervangen door naar sequentiële i/o, zodat de koppen van de harde schijven minder verplaatsingen moeten maken en de drives meer iops kunnen leveren. Om de overhead van het copy-on-write-model te beperken worden schrijfacties samengevoegd in transactiegroepen die enkele seconden duren.
Naast hogere random write-prestaties heeft copy-on-write als voordeel dat zfs zeer snel snapshots van het bestandssysteem kan maken. Een snapshot maakt het mogelijk om terug te keren naar de staat van een bestandssysteem op een bepaald moment in de tijd. Ook is het mogelijk om snel beschrijfbare klonen van een bestandssysteem te maken. De gekloonde bestandssystemen kunnen ieder hun eigen wijzigingen ten opzichte van de oorspronkelijke data bevatten, en de gegevens die sinds het maken van de kloon niet meer zijn gewijzigd, kosten geen extra ruimte.
Caching
Zfs voert op verschillende lagen caching uit om de prestaties te verbeteren. De read cache bestaat uit twee niveaus: arc en l2arc. Arc staat voor adaptive replacement cache, een algoritme dat ranglijsten bijhoudt van zowel meest gebruikte als laatst geraadpleegde gegevensblokken. Hiermee behaalt het arc-algoritme betere prestaties dan het veelgebruikte least recently used-algoritme. Een incidentele scan van een zeer groot bestand zal er bij de adaptive-replacement-strategie niet voor zorgen dat de gehele cache wordt vervangen door data die later niet meer geraadpleegd wordt.
De arc bevindt zich in het werkgeheugen. Op een machine die als dedicated storage server wordt ingezet, zal bijna het gehele geheugen voor de arc worden gebruikt. Zfs biedt de mogelijkheid om een secundaire leescache, de l2arc, op snelle block devices zoals ssd's aan te maken. Dit maakt het mogelijk om grote storage pools te creëren op energiezuinige harddisks, waarvan de meestgebruikte gegevens benaderd kunnen worden met een snelheid die vergelijkbaar is met die van een ssd. Elke storage pool heeft zijn eigen arc en eventuele l2arc.
De mapping van gegevensblokken in de l2arc wordt bijgehouden in ram en gaat verloren bij een reboot. De ruimte die nodig is voor de mapping van de l2arc gaat ten koste van geheugen dat anders voor bijvoorbeeld de arc beschikbaar zou zijn. De l2arc is dus minder zinvol op systemen die regelmatig worden uitgezet of opnieuw worden opgestart.
Het geheugengebruik hangt af van de blokgrootte van het bestandssysteem. Bij een blokgrootte van 8kB kan er per gigabyte geheugen een l2arc van 40GB bijgehouden worden. Een blokgrootte van 128kB maakt een l2arc van 640GB per gigabyte werkgeheugen mogelijk. De maximale omvang van de l2arc kan berekend worden door de hoeveelheid werkgeheugen te vermenigvuldigen met vijf maal de blokgrootte.
Ook niet-synchrone schrijfoperaties worden door zfs in de adaptive replacement cache meegenomen. De schrijfoperaties worden gebundeld weggeschreven in zogeheten transaction groups of txg's, die standaard vijf seconden open staan om schrijfacties te ontvangen. Na het sluiten van een txg worden de wijzigen weggeschreven naar de storage pool en wordt tegelijkertijd een nieuwe txg geopend om schrijfoperaties te verzamelen. Als zfs merkt dat een txg wordt afgesloten terwijl de vorige txg nog bezig is met synchroniseren, zal de snelheid waarmee applicaties naar de txg schrijven worden teruggeschroefd. Zo wordt de doorvoersnelheid afgestemd op de prestaties van de pool.
De laatste operatie in het synchroniseren van een txg is het schrijven van een überblok dat het nummer van de transactiegroep bevat. Als door stroomuitval een transactiegroep niet volledig weggeschreven kon worden, kan zfs de laatst voltooide txg herkennen aan het überblok met het hoogste nummer. Omdat bestaande gegevens vanwege het copy-on-write-transactiemodel nooit worden overschreven is een zfs-bestandssysteem altijd in een consistente staat: een transactiegroep wordt volledig in het bestandssysteem opgenomen, of helemaal niet, maar nooit half. In het ergste geval gaan er enkele seconden aan schrijfacties verloren.
Synchrone schrijfoperaties zijn een bekende bron van prestatieproblemen omdat ze een applicatie blokkeren totdat de schrijfacties hebben plaatsgevonden op een stabiel medium, zoals een harde schijf of ssd. Bovendien moeten synchrone schrijfacties worden uitgevoerd in de volgorde waarin ze zijn binnengekomen. Het optimaliseren van de volgorde om kopverplaatsingen van harde schijven te beperken is niet toegestaan, en ook mogen de schrijfoperaties niet gecached worden in vluchtig geheugen zonder battery backup.
Om de prestaties en integriteit van synchrone schrijfacties te waarborgen maakt zfs gebruik van de zfs intent log, beter bekend als de zil. In dit log worden synchrone schrijfoperaties bijgehouden. De zil bevat genoeg informatie om schrijfoperaties opnieuw af te spelen in het geval van stroomuitval. Bij kleine schrijfacties wordt de data in de zil opgeslagen; bij grote schrijfacties gaat de data direct naar de pool terwijl de block pointer naar deze gegevens in de zil wordt opgeslagen. Op het moment dat de transacties worden geïntegreerd in het bestandssysteem, hoeft geen data van de zil naar de disks in de pool te worden gekopieerd: alleen de referenties worden geactualiseerd.
De zil wordt verwijderd bij het afsluiten van het bestandssysteem. Als er bij het mounten van het bestandssysteem wordt geconstateerd dat er nog een zil met actieve transacties aanwezig is, worden deze transacties opnieuw afgespeeld tot het moment dat de laatste succesvolle synchronisatie plaatsvond.
De zil bevindt zich normaal gesproken op de disks in de pool. Betere prestaties zijn mogelijk door ssd's als logdevice aan de pool toe te voegen. Om de beschikbaarheid van de zil te garanderen moeten de log drives in een mirror geplaatst worden, zodat de zil niet verloren gaat als een van de log drives uitvalt. Ook ssd's met supercondensatoren zijn handig: deze zijn bij stroomuitval in staat om lopende schrijfacties te voltooien, zodat een consistente staat van de zil wordt gegarandeerd.
Het ruimtegebruik op de zil is gering. In het uiterste geval moet de inhoud van één transactiegroep opgeslagen worden. De maximum grootte van een txg is afhankelijk van de hoeveelheid geheugen in het systeem en de snelheid waarmee er naar dit geheugen geschreven kan worden. Op de meeste systemen kan een txg niet groter worden dan enkele gigabytes, maar het ruimtegebruik zal in de praktijk minder zijn dan enkele honderden megabytes.
/i/1330086673.png?f=imagenormal "Zfs write pipeline met en zonder log-device")
Deduplicatie en compressie
Zfs beschikt over twee ruimtebesparende features: deduplicatie en compressie. Deduplicatie is een compressiemethode die redundante data in een gegevensset elimineert. In plaats van dezelfde data meerdere keren op te slaan wordt er een enkele kopie van de data opgeslagen. Bij de volgende keren dat dezelfde data opduikt, wordt een verwijzing naar de eerste kopie opgeslagen. Deduplicatie vindt plaats op blokniveau. Bestanden in een zfs-bestandssysteem hebben een variabele blokgrootte die afhankelijk is van de grootte van een bestand. Zvolumes die als scsi-target in een storage area network geëxporteerd worden, hebben standaard een blokgrootte van 8kB. Dit kan handmatig verhoogd worden tot het maximum van 128kB. Een grotere blokgrootte levert minder overhead op en reduceert het geheugengebruik van het deduplicatieproces.
Zfs is van nature geschikt voor duplicatie omdat er toch al op blokniveau checksums worden gegenereerd. Zfs gebruikt na het inschakelen van deduplicatie de sterkere maar cpu-intensievere sha256-hashmethode om blokken met een unieke inhoud te herkennen. Bij een matchende checksum kan eventueel de inhoud van het blok worden vergeleken met het blok dat een identieke checksum heeft. Hiermee worden hash-collisions, die bij sha256 kunnen voorkomen met een waarschijnlijkheid van twee tot de macht 256, definitief uitgesloten worden. Verificatie kan ook veilig worden gebruikt met de zwakkere en snellere hashmethode fletcher4, die zfs standaard voor het genereren van checksums gebruikt.
Deduplicatie wordt in enterprise-opslagsystemen veel toegepast om het ruimtegebruik terug te dringen van bijvoorbeeld backup-, mail- en fileservers, waarop dezelfde content - bijvoorbeeld email-attachments of grotendeels identieke images van virtuele machines - soms tientallen keren voorkomen. Op systemen met veel redundante data kan dedupe de prestaties verbeteren doordat er minder data naar de pool geschreven wordt. Is de deduperatio laag dan zullen de prestaties slechter zijn vanwege de toegevoegde overhead.
Naast deduplicatie van identieke gegevensblokken biedt zfs de mogelijkheid om de gegevensblokken zelf te comprimeren. Op goed comprimeerbare data maakt compressie betere prestaties mogelijk. De efficiënte van het compressieproces is beter als er met een grote blokgrootte wordt gewerkt. Zfs ondersteunt de compressie-algoritmen lzip en gzip met instelbare compressiesterktes.
Replicatie
Zfs ondersteunt online replicatie. Met de zfs send- en zfs recv-commando's kunnen wijzigingen in het bestandssysteem naar een ander systeem worden gekopieerd. Als uitgangspunt dient een snapshot dat voor het opstarten van de replicatie naar het remotesysteem is geëxporteerd. Vervolgens stuurt zfs de gewijzigde blokken naar dat systeem.
Comstar
Naast het zfs-bestandssysteem heeft Sun nog een ander mooi opensourcepakket voor opslagsystemen afgeleverd. Comstar is de afkorting voor Common Multiprotocol Scsi Target en is een softwareframework waarmee een machine met Solaris - of een daarvan afgeleid besturingssysteem - kan worden ingezet als scsi-target.
In een scsi-omgeving is het target het eindpunt dat wacht op binnenkomende scsi-commando's en de gevraagde I/O-transfers levert. Scsi-sessies worden opgezet door een scsi-initiator die commando's naar een target stuurt. Normaal gesproken is de initiator een computer en het target een opslagapparaat dat toegang verschaft tot één of meerdere zogeheten logical units. Een logical unit is een drive die door middel van het scsi-protocol of aanverwante protocollen zoals fibre channel en iscsi wordt aangesproken. Een logical unit wordt geïdentificeerd met een logical unit number of lun. Hoewel het technisch niet correct is, wordt de term lun in vakjargon vaak gebruikt om een drive aan te duiden.

Comstar heeft ondersteuning voor verschillende soorten scsi-interfaces. Naast serial attached scsi worden scsi-targets met fibre channel, fibre channel over ethernet, iscsi en srp ondersteund. De laatstgenoemde is een techniek voor de acceleratie van scsi-commando's over infiniband, een netwerkinterface die veel wordt toegepast in high performance computing en die snelheden van 40Gbps per poort mogelijk maakt.
De computers in een infiniband-netwerk hebben door middel van remote dma direct toegang tot elkaars geheugen zonder tussenkomst van de besturingssystemen op deze computers. Dat maakt zogeheten zero-copy networking mogelijk, waarbij er geen noodzaak is om gegevens te kopiëren tussen het geheugen van een applicatie en de databuffers van het besturingssysteem. Het scsi rdma-protocol vertaalt scsi-commando's naar remote dma-operaties en kan zo hogere doorvoersnelheden halen dan wanneer er iscsi via ip over infiniband wordt gebruikt. Ook is de processorbelasting lager.
Comstar kan een logical unit toegankelijk maken via verschillende interfaces. Dit kan desgewenst tegelijkertijd, dankzij ondersteuning voor multipath i/o of mpio. De verschillende paden naar een logical unit kunnen gebruikt worden voor failover of om de prestaties te verbeteren. Het besturingssysteem op de scsi-initiator moet wel mpio ondersteunen om de verschillende paden te benutten. Zonder ondersteuning voor mpio zal het besturingssysteem simpelweg de afzonderlijke blockdevices zien.

Helaas heeft Microsoft besloten om mpio enkel beschikbaar te maken in Windows Server 2008 en het achterwege te laten in Windows 7. Dat is jammer, want mpio is een erg bruikbare techniek om de bandbreedte van de poorten op dual- en quadport fibrechanneladapters te combineren. Ook kan het uitstekend gebruikt worden om meerdere gigabit-ethernetpoorten samen te voegen. Tot MacOS X Snow Leopard had Apple ondersteuning voor device-specifieke multipathing, die enkel werkte met bepaalde fibrechannel-opslagarrays. In MacOS X Lion werd er ondersteuning toegevoegd voor het alua-controllermodel, een gestandaardiseerde methode voor multipathing die eveneens door Windows Server 2008, Solaris en Linux wordt ondersteund. Het alua-model maakt het mogelijk om een logical unit met minimale configuratie via verschillende paden toegankelijk te maken.

Het Comstar-framework kan overweg met generieke opslagcontrollers. Om een sas- of fibrechannelcontroller als scsi-target in te zetten, moet de normale initiator-driver vervangen worden door een target-driver. Target-drivers zijn beschikbaar voor LSI-sas-controllers die in vrijwel alle systemen met een onboard sas-controller of een losse sas-hostbusadapter worden gebruikt. Fibrechannel-targetondersteuning is aanwezig voor adapters van onder andere Qlogic en Emulex. Bij fibrechannel-adapters kan de keuze tussen target- of initiatormodus per poort gemaakt worden. Op een tweepoorts adapter is het dus mogelijk om één poort als initiator te laten functioneren en de andere als target.
Zfs en Comstar
De combinatie zfs en Comstar maakt het mogelijk om opslagnetwerken te bouwen waarin data op blokniveau wordt gedeeld tussen systemen die zijn verbonden via sas, fibre channel, ethernet of Infiniband. Die achterliggende opslag kan gebruikmaken van de voordelen van zfs, zoals de hoge data-integriteit en de ondersteuning voor ssd-caching en snapshots. De volumemanager en het bestandssysteem in zfs worden in dit geval uit elkaar getrokken: zfs exporteert een deel van de storage pool als block device, een zogeheten zvol, dat via Comstar als logical unit toegankelijk wordt gemaakt voor scsi-initiators die met het Comstar scsi-target zijn verbonden. Zfs heeft geen kennis van het bestandssysteem op het zvol: het bestandssysteem wordt beheerd door het besturingssysteem op de initiator. Voor dit besturingssysteem functioneert een logical unit in een opslagnetwerk op dezelfde wijze als andere block devices zoals lokale sata-harde schijven.

Hiermee komen we bij een belangrijk verschil tussen een storage area network (san) en network attached storage (nas). Bij een nas wordt data op bestandsniveau gedeeld. Het bestandssysteem bevindt zich op de nas-server en een tussenliggend protocol zoals cifs onder Windows en nfs op unixachtigen maakt de bestanden op de nas toegankelijk voor de clients en handelt schrijfacties van de clients naar de bestanden af. De data op een logical unit in een san kan niet zondermeer gedeeld worden tussen twee scsi-initiators. De besturingssystemen op de initiators zullen moeten gebruikmaken van een clustered bestandssysteem om te voorkomen dat een schrijfactie van de ene client voor een corrupt bestandssysteem bij de andere client zorgt. Bij clustered bestandssystemen communiceren de clients onderling via bijvoorbeeld een ip-netwerk over wijzigingen die zij maken in het bestandssysteem. Een voorbeeld van een clustered bestandssysteem is Xsan van Apple.
In dit artikel zullen we ons concentreren op het gebruik van zfs in een storage area network. Een volwaardig san in een thuisomgeving is voor netwerkinterfaces anders dan gigabit-ethernet nog erg kostbaar vanwege de hoge prijzen van gebruikte fibrechannel- en infiniband-switches. Point-to-point verbinding zijn een stuk goedkoper en op adapters met meerdere poorten is het alsnog mogelijk om twee of vier clients aan te sluiten. Een san voor thuis is bijvoorbeeld interessant om grote hoeveelheden opslag toegankelijk te maken op een desktop of workstation met behoud van prestaties maar zonder de nadelen zoals de geluidsproductie van acht of meer lokale harde schijven. De opslagserver kan immers ergens geplaatst worden waar hij geen overlast veroorzaakt. Door opslag die nodig is voor een workstation en mediaspelers of andere data die normaal gesproken op een losse nas geplaatst zou worden te consolideren kunnen de harde schijven die hiervoor nodig zijn altijd tegelijkertijd ingezet worden om optimale prestaties te leveren. De functionaliteit van een san en een nas kan prima op dezelfde server gecombineerd, hoewel in dat geval uiteraard niet dezelfde data gedeeld kan worden. Wel is het mogelijk om de data in een san via filesharing in het besturingssysteem op de scsi-initiator te delen.
Bouw van een zfs-server: software
Tweakers die aan de slag willen met het bouwen van een zfs-server moeten een groot aantal keuzes maken op het gebied van hardware en software. Er kunnen een aantal algemene adviezen gegeven worden. Verderop in dit artikel kijken we naar het aantal harde schijven, het raid-level en de hoeveelheid geheugen, en bespreken we het nut van caching-ssd's aan de hand van enkele benchmarks.
Software
Zfs werd oorspronkelijk ontwikkeld door Sun als onderdeel van zijn Solaris-besturingssysteem. In 2005 werd een groot deel van de codebase van Solaris onder de cddl-licentie vrijgegeven en werd het OpenSolaris-opensourceproject opgericht. Ook zfs werd onder een opensourcelicentie uitgebracht. Na de overname van Sun besloot Oracle in 2010 om de distributie van OpenSolaris en de updates voor de broncode van de Solaris-kernel te staken. Solaris 11, de huidige versie van het besturingssysteem, werd daarmee feitelijk weer een closedsource besturingssysteem.
Ontwikkelaars uit de OpenSolaris-community brachten daarop een fork van OpenSolaris uit, die OpenIndiana heet. De naam is afgeleid van Project Indiana, een werkgroep van Sun die zich bezighield met het maken van een binaire distributie van de OpenSolaris-sourcecode. OpenIndiana maakt gebruik van de Illumos-kernel. Illumos werd opgericht om een echte opensourcevariant van Solaris te maken, waarin alle closedsource-onderdelen door open varianten zouden worden vervangen. De laatste versie van OpenIndiana werd uitgebracht in september 2011.
Een andere fork van OpenSolaris is Nexenta OS, dat wordt ontwikkeld door de commerciële onderneming Nexenta Systems en dat specifiek is bedoeld voor gebruik in opslagservers. Nexenta Systems levert op basis van Nexenta OS het eigen besturingssysteem genaamd NexentaStor dat beschikt over gebruiksvriendelijke webbased beheerstools. Er is een gratis community-editie van NexentaStor die een maximum van 18TB opslagruimte toestaat. Recentelijk werd besloten om ook NexentaStor verder te ontwikkelen op basis van de Illumos-kernel.
/i/1330094863.png?f=imagenormal "NexentaStor screenshot")
Een andere mogelijkheid om zfs kosteloos onder Solaris uit te proberen is Oracle Solaris Express. Dit besturingssysteem heeft echter sterk beperkende licentievoorwaarden, die onder meer commercieel gebruik verbieden. Ook worden er geen updates uitgebracht om bestaande installaties bij te werken tot de nieuwste versie.
Zfs is verder aanwezig in FreeBSD en NetBSD, en in afgeleiden zoals FreeNAS en Zfsguru, die als doel hebben om gebruiksvriendelijke opslagfeatures te bieden. Het Comstar-framework ontbreekt in deze besturingssystemen.
Gebruikers die block storage willen delen in een storage area network zijn het beste uit met een Solaris-variant vanwege de eerder besproken features van het Comstar-framework. OpenIndiana is de meest voor de hand liggende optie als beheer via de command-line geen probleem is. Er is een ruime beschikbaarheid van tutorials en blogs waarin het beheer van zfs en Comstar via de command-line wordt uitgelegd.
Klikgrage tweakers kunnen de community-editie van NexentaStor overwegen of de webbased beheertool Napp-it onder OpenIndiana installeren. Niet alle features van zfs en Comstar kunnen met Napp-it gebruikt worden. Zo zal er voor het configureren van een fibrechannel-target op de command-line teruggegrepen moeten worden. Wij hebben voor onze tests gekozen voor OpenIndiana vanwege het opensource-karakter van deze distributie en de beschikbaarheid van het Comstar-framework.
/i/1330095200.png?f=imagenormal "Napp-it screenshot")
Bouw van een zfs-server: hardware
De installatie van OpenIndiana is eenvoudig zolang er goed ondersteunde hardware wordt gebruikt. Een van de belangrijkste keuzes is daarbij die voor een storage controller.
Zfs heeft ten opzichte van andere bestandssystemen en volumemanagers als voordeel dat er goede prestaties behaald kunnen worden zonder dat een hardwarematige raid-adapter met een eigen processor en cachegeheugen nodig is. De prijzen van dergelijke adapters variëren van 250 euro voor een vierpoorts instapmodel tot 900 euro voor een kaart met 24 poorten. Een zfs-server kan volstaan met de ahci-poorten op het moederbord of een losse sas-hostbusadapter.
De sas-controllers van LSI hebben de beste ondersteuning in Solaris en BSD. Er kan onderscheid gemaakt worden tussen de LSI SAS1064- en SAS1068-controllers met respectievelijk vier en acht 3Gbps-sas-poorten, en de LSI SAS2004, SAS2008 en SAS2016 met respectievelijk vier, acht en zestien 6Gbps-sas-poorten. De meest toegepaste varianten zijn de achtpoorts SAS1068- en SAS2008-controllers.
Er is op dit moment nauwelijks onderscheid in de nieuwprijzen van hostbusadapters met SAS1068- en SAS2008-controllers. Een populaire sas 6g-controller is de IBM ServeRaid M1015 die al voor 117 euro te koop is. De Supermicro AOC-USASLP-L8i met de LSI SAS1068 staat in de Pricewatch voor prijzen vanaf 116 euro. Op eBay kunnen sas-adapters voor nog lagere prijzen op de kop getikt worden. Sas 3g-adapters worden aangeboden voor prijzen vanaf ongeveer 45 euro en sas 6g-adapters voor 65 euro of meer. Servermoederborden kunnen vaak met een onboard LSI-sas-controller worden geleverd, of zijn standaard al van zo'n controller voorzien.

Sas-hostbusadapters met een LSI-controller worden vaak geleverd met Integrated Raid-firmware. Omdat zfs de raidfunctionaliteit van de sas-controller niet gebruikt, heeft het de voorkeur om de IR-firmware te vervangen door Initiator-Target-firmware. In IT-modus functioneert de adapter als een kale sas-controller zonder raidfunctionaliteit.
Losse sata-controllers die op moederborden en in goedkope pci express-sata-adapters worden geïntegreerd, worden niet in alle gevallen ondersteund. De beste opties zijn JMicrons JMB362-, JMB363- en JMB366-ahci-controllers. Ook de Silicon Image Sil3132 is ook nog een optie. De 88SE9128, 88SE9125 en 88SE9120 van Marvell, die op veel moederborden worden toegepast, worden in Solaris niet ondersteund. Datzelfde geldt voor Marvells 88SE6485-, 88SE6480-, 88SE9485- en 88SE9480 sas-controllers, die op enkele serverborden worden geleverd en geïntegreerd zijn in bepaalde sas-hostbusadapters van Areca en HighPoint. Ook deze dienen dus vermeden te worden.
Het heeft de voorkeur om in eerste instantie de ahci-poorten van recente Intel- of AMD-chipsets te gebruiken. Als er meer poorten nodig zijn, kan er een sas-hostbusadapter met een LSI sas-controller worden bijgeplaatst; er kan ook voor een moederbord worden gekozen dat een dergelijke controller al aan boord heeft.
Naast de kostenbesparing ten opzichte van een hardwarematige raid-adapter biedt zfs een betere schaalbaarheid doordat storage pools probleemloos meer sata- en sas-controllers kunnen gebruiken. Het gebruik van sas-expanders om het aantal sas-poorten op te krikken is daarom pas zinvol zodra er niet voldoende pci express-slots voorhanden zijn om het aantal gewenste poorten met acht- of zestienpoorts sas-hba's te realiseren. Sas-expanders zijn meestal duurder dan een extra achtpoorts adapter en het energieverbruik is vrijwel gelijk. In theorie zijn ook de prestaties minder, hoewel dat in de praktijk zelden een beperking zal zijn omdat sas-expanders normaal gesproken met een wide-port van vier poorten met de sas-controller zijn verbonden. De bandbreedte van een wide-port is 1,2GBps of 2,4GBps, afhankelijk van de poortsnelheid.
De keuze van het moederbord en de processor hangt vooral af van de vraag hoeveel sata-poorten en pci express-slots er nodig zijn, en welk energieverbruik acceptabel is. Zfs vraagt geen snelle processor en kan goed overweg met multicore-processors. Recente AMD- en Intel-platformen worden goed ondersteund. In het zuinigeservertopic op ons forum kun je ervaringen met energiezuinige processors en moederborden vinden. Solaris en OpenIndiana ondersteunen de meest voorkomende netwerkcontrollers, maar raadpleeg voor de zekerheid de hardware compatibility list van Oracle.
Zfs houdt van veel geheugen. Ram wordt onder andere gebruikt voor de adaptive replacement cache, als buffer voor transaction groups die naar de pools geschreven moeten worden, en om verwijzingen naar een eventuele l2arc bij te houden. Het inschakelen van deduplicatie leidt ook tot een verhoogd geheugengebruik. Vanwege de huidige lage geheugenprijzen is het aan te bevelen om een moederbord met vier dimm-slots uit te zoeken, zodat een systeem goedkoop van 16GB ram voorzien kan worden: de prijzen van unbuffered 8GB-modules zijn namelijk nog relatief hoog. Voor meer dan 16GB geheugen is een servermoederbord met ondersteuning voor registered memory aan te bevelen.
Voor systemen tot acht harde schijven volstaat een standaard towerbehuizing. Bij meer disks is het fraaier om hotswap-drivebays te gebruiken. Deze nemen een tot drie 5,25"-bays in beslag en bieden ruimte aan maximaal vijf harde schijven. Voor opslagsystemen met meer dan twaalf disks is een 19"-rackmount de mooiste oplossing. Norco levert betaalbare rackmounts die weliswaar niet van hetzelfde kaliber zijn als professionele rackmounts, maar die voor thuisgebruik erg geschikt zijn. Met een LackRack van Ikea kan iedere thuisgebruiker zijn rackmount thuis ophangen. Inspiratie kan worden opgedaan in het 10TB+ storage showoff-topic.

Installatie en configuratie
De prestaties van zfs en Comstar werden getest op een server met een Tyan S8010-moederbord, een Opteron 4122-quadcore en 32GB ram. De onboard sas2008-controller van LSI kreeg gezelschap van een IBM ServeRaid M1015-sas-raid-adapter om het aantal sas 6g-poorten naar zestien stuks te verhogen. Voor snelle communicatie met de buitenwereld werd de machine voorzien van een Qlogic QLE2464-fibrechanneladapter. De onderdelen werden ondergebracht in een Norco RPC-4216-behuizing met twee Chieftec-hotswapbays voor zes 2,5"-sata-drives. In de behuizing werden twaalf Seagate Barracuda Green 5900.3 2TB-harddisks en zes Samsung SSD 830 64GB-ssd's geschoven, samen met een OCZ Vertex 120GB die als bootdrive dienstdoet. De fibrechannel- en sas-hostbusadapters werden op eBay gekocht.


De benchmarks werden gedraaid op een van onze twee standaard storage-testsystemen, die zijn gebaseerd op een Intel H67-moederbord met een Core i5 2500K-processor. Het testsysteem werd voor deze gelegenheid voorzien van Windows Server 2008 R2 zodat er multipath i/o kon worden gebruikt. Ook kreeg dit systeem een Qlogic QLE2464-fibrechannel-hba. Hiermee kon een viervoudige point-to-point-verbinding tussen het testsysteem en de server opgezet worden met een totale bandbreedte van 1,6GBps.

We begonnen de installatie met het updaten van de firmware op de fibre channel-adapters en de sas-controllers. De Integrated Raid-firmware op de onboard sas-controller en de MegaRaid-firmware op de IBM ServeRaid M1015 werden vervangen door Initiator Target-firmware van een LSI SAS9211-8i. Instructies over het flashen van de firmware op de onboard controller en de IBM-adapter kunnen op ServeTheHome en het LimeTech-forum worden gevonden.
Met behulp van OpenSolaris Live USB Creator werd er een bootable usb-stick met de installatiebestanden van OpenIndiana 151a geprepareerd. Het installatieproces bleek een kwestie van een aantal eenvoudige vragen beantwoorden. De hardware in onze machine werd direct herkend.
Na voltooing van de installatie werden de storage pools geconfigureerd. Dit kan vanaf de command line, of, als Napp-it is geïnstalleerd, met de browser. Zfs heeft een heldere syntax waarmee de gebruiker snel vertrouwd raakt, maar het is natuurlijk wel handig om eerst wat ervaring op te doen voordat je je gevoelige data aan een zfs-machine toevertrouwt.
Solaris herkent de drives in het systeem op basis van een unieke identifier. De identifier zorgt ervoor dat een harde schijf of ssd een andere poort kan krijgen, terwijl de disk herkenbaar blijft. Bij het maken van een storage pool geef je aan welke id's onderdeel van de pool zijn en in welke raidtype ze geconfigureerd moeten worden. De id's kunnen achterhaald worden met behulp van het format-commando.
Na het aansluiten van de Samsung 830-ssd's merkten we dat deze drives geen uniek id kregen, waardoor alleen de eerste drive aan een pool toegevoegd kon worden. Dit probleem kon verholpen worden door de multipath-optie in de mpt_sas-driver van LSI uit te zetten, met het onderstaande commando:
stmsboot -D mpt_sas -d
Hierna verschenen de drives met een uniek id in de lijst met disks:
femme@openindiana:~# format
Searching for disks...done
AVAILABLE DISK SELECTIONS:
0. c3d1 <Unknown-Unknown-0001 cyl 3261 alt 2 hd 255 sec 63>
2. c8t5000C50037C28658d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
3. c9t5000C50037876087d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
4. c10t5000C50037AB21E0d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
5. c16t5000C50037C38A34d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
6. c17t5000C50037C37DC3d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
7. c18t5000C50037C37CB1d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
8. c19t5000C50037B4CD12d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
9. c20t5000C50037AACC25d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
10. c21t5000C50037AA751Fd0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
11. c22t5000C50037A08128d0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
12. c23t5000C50037C1A26Dd0 <ATA-ST2000DL003-9VT1-CC32-1.82TB>
13. c25t5002538043584D30d0 <ATA-SAMSUNG SSD 830-3B1Q-59.63GB>
14. c26t5002538043584D30d0 <ATA-SAMSUNG SSD 830-3B1Q-59.63GB>
15. c27t5002538043584D30d0 <ATA-SAMSUNGSSD830-3B1Q cyl 9965 alt 2 hd 224 sec 56>
16. c28t5002538043584D30d0 <ATA-SAMSUNGSSD830-3B1Q cyl 9965 alt 2 hd 224 sec 56>
disk (enter its number):
Om een stripeset van de eerste twee harde schijven in ons systeem te gebruiken voor het aanmaken van een storage pool met de naam 'tank', gebruiken we het volgende commando:
zpool create tank c8t5000C50037C28658d0 c9t5000C50037876087d0
Net zo makkelijk is het aanmaken van een mirror van de bovenstaande schijven:
zpool create tank mirror c8t5000C50037C28658d0 c9t5000C50037876087d0
Voor een raid-10-opstelling van vier schijven is het commando:
zpool create tank mirror c8t5000C50037C28658d0 c9t5000C50037876087d0 mirror c10t5000C50037AB21E0d0 c16t5000C50037C38A34d0
De opdracht die een raid-z van vier disks aanmaakt ziet er als volgt uit:
zpool create tank raidz c8t5000C50037C28658d0 c9t5000C50037876087d0 c10t5000C50037AB21E0d0 c16t5000C50037C38A34d0
En een stripe van twee raid-z-vdev's met ieder drie disks wordt aangemaakt met:
zpool create tank raidz c8t5000C50037C28658d0 c9t5000C50037876087d0 c10t5000C50037AB21E0d0 raidz c16t5000C50037C38A34d0 c17t5000C50037C37DC3d0 c18t5000C50037C37CB1d0
De samenstelling en de i/o-statistieken van onze 'tank'-storage pool kan bekeken worden met het volgende commando. In dit geval vindt er elke vijf seconden een refresh plaats:
zpool iostat -v tank 5
In de pool kan een zvol worden aangemaakt, die vervolgens via Comstar als scsi-target geëxporteerd kan worden. Met het volgende commando wordt een zvol aangemaakt met een blokgrootte van 128K en een capaciteit van 250GiB:
zfs create -V 250G -o volblocksize=128K tank/testvolume
Om een fibrechannel-adapter als scsi-target in te zetten, moet er een targetmode-driver op de gewenste poorten worden aangezet. Informatie over het inschakelen van targetmode-drivers en het configureren van Comstar kan gevonden worden in de blogs van Prefetch Technologies (Emulex-adapters) en IT From All Angles (Qlogic-adapters).
Na het configureren van een logical unit en een scsi-target zal het besturingssysteem op de scsi-initiator een nieuw block device zien. Dit block device kan op de gebruikelijke wijze gepartitioneerd en geformatteerd worden. Als er fibrechannel-adapters met meerdere poorten worden gebruikt, kan een logical unit via verschillende paden aan de host worden aangeboden. Windows zal in dat geval alleen het eerste pad gebruiken. De mpio-service van Windows Server 2008 is nodig om i/o over meerdere paden te loadbalancen.
Optimalisatie
Op de komende pagina's zullen we de invloed van het raid-level, het aantal disks in een storage pool, caching, compressie en deduplicatie onderzoeken. Voordat we begonnen met deze benchmarks hebben we eerst gezocht naar de optimale instellingen voor een storage pool. We gingen hierbij uit van een storage pool met acht disks in raid 10. Het tunen van de instellingen bleek zeer de moeite waard.
Alignment
Harde schijven hebben van oudsher een sectorgrootte van 512 bytes. Op moderne harddisks met een opslagcapaciteit van meerdere terabytes zorgt deze kleine sectorgrootte voor onnodige overhead. Er is daarom behoefte ontstaan aan vergroting van de sectoren. Disks met een capaciteit van 2TB en hoger hebben daarom vaak een sectorgrootte van 4K. Om compatibiliteit met oudere besturingssystemen en software te waarborgen, is er een standaard ontwikkeld die nieuwe besturingssystemen de sectorgrootte van 4kB laat gebruiken terwijl oudere besturingssystemen via een conversie sectoren van 512 bytes kunnen benaderen. Niet alle harde schijven implementeren deze standaard. Het gevolg is dat zfs op bepaalde large-sectordrives uitgaat van een sectorgrootte van 512 bytes. Zfs lijnt de storage pool in dat geval uit op 512byte-grenzen, waardoor blokken in een storage pool op een harde schijf met 4kB-sectoren meer dan één sector kunnen beslaan. Dit kan de prestaties negatief beïnvloeden.
De verkeerde alignment bleek ook voor te komen bij de Seagate Barracuda Green 5900.3 2TB-disks in ons testsysteem. Met behulp van een aangepaste zpool-binary hebben we handmatig storage pools met een alignment op 4096 bytes aangemaakt. De alignment kan met het volgende commando worden gecontroleerd:
zdb -C tank | grep ashift
Een waarde van 9 komt overeen met een alignment op 29 = 512 bytes.
In diverse forumtopics over de configuratie van Comstar-targets wordt aangeraden om zowel de blokgrootte van het zvol als de sectorgrootte van de logical unit die aan de scsi-initiator wordt gepresenteerd, overeen te laten komen met de blokgrootte van het bestandssysteem dat de host op de logical unit draait. Standaard heeft ntfs een blokgrootte van 4kB. Een Comstar-target heeft standaard een sectorgrootte van 512 bytes. De host ziet dus een block device met een sectorgrootte van 512 bytes, terwijl de achterliggende disks in ons geval een sectorgrootte van 4kB hebben. We hebben daarom getest welke invloed een logical unit met een sectorgrootte van 4kB op de prestaties heeft. De zvol-blokgrootte hebben we op de standaardwaarde van 8kB gelaten omdat die naar ons gevoel al erg laag was.


Een correcte alignment bleek inderdaad een positief effect te hebben op de doorvoersnelheden. Vergelijkbare verschillen waren ook te vinden bij de sequentiële doorvoer. Een logical-unit-sectorgrootte van 4kB had een afname van de doorvoersnelheid tot gevolg. Ook werkten sommige benchmarks niet meer omdat ze uitgingen van een sectorgrootte van 512 bytes.
In de trace-based benchmarks was het verschil tussen een storage pool met een incorrecte en een correcte alignment minimaal. Wel presteerde de logical unit met 4kB-sectoren duidelijk minder goed dan die met de standaard sectorgrootte van 512 bytes.
Zvol-blokgrootte
Zfs hanteert normaal gesproken een variabele blokgrootte die afhankelijk is van de bestandsgrootte. Bij een zvol heeft zfs echter geen kennis van de grootte van de bestanden, omdat zfs in dat geval een deel van een storage pool als block device exporteert naar een host die er zijn eigen bestandssysteem op draait. Zfs valt dan terug naar een vaste blokgrootte van 8kB. Dat is erg weinig in vergelijking met de optimale stripe-size die bij de meeste raidcontrollers varieert van 128kB tot 256kB.
De reden is dat de responstijd van kleine i/o's op een raid-array van harddisks voornamelijk afhankelijk is van het wachten op de positionering van de schijfkoppen. Door meerdere harde schijven aan een kleine transfer te laten werken, is de bottleneck die harde schijf die het langst over het positioneren van zijn koppen doet. Als er een grotere stripe size wordt gebruikt, kunnen kleine requests in de meeste gevallen worden afgehandeld door een enkele disk in de stripeset.
In een zfs-storagepool is elk blok een volledige stripe over alle drives in de pool, waardoor altijd alle drives in een pool benaderd moeten worden om een blok in te lezen. Toch is het aannemelijk dat de standaard blokgrootte van 8kB voor zvol's onnodig veel overhead veroorzaakt op een pool met harde schijven als achterliggende opslag. We hebben de blokgrootte van het zvol stapsgewijs verhoogd totdat we de optimale instelling bereikten. De beste prestaties werden geleverd bij een blokgrootte van 128kB, wat ook het maximum is.

Aanvankelijk waren we teleurgesteld in de prestaties van de storage pool met acht disks in raid 10. Met de standaard zvol-blokgrootte van 8kB scoorde het systeem 345 punten in de StorageMark 2011-index en slechts 157 punten in de Boot StorageMark 2011-index. Een enkele - lokale - Seagate Barracuda Green 2TB haalt 171 punten in de workstationindex en 170 punten in de bootindex. Met de blokgrootte op 128K zien de resultaten er echter al een stuk rooskleuriger uit: in de workstationindex is de zfs storage pool bijna drie keer zo snel als een enkele lokale disk. De bootindex is een factor anderhalf hoger.
Prefetching en concurrency
Als laatste hebben we gekeken of er winst is te halen uit het tunen van de vdev prefetch en het aantal gelijktijdige i/o's per vdev. Zfs beheert per vdev een read-ahead-cache die standaard een omvang heeft van 10MB; leestransfers van minder dan 64kB worden vergroot naar 64kB in de hoop dat er dan later bruikbare gegevens van de disk worden gelezen.
Harde schijven hebben bij het uitvoeren van random leestransacties de meeste tijd nodig voor het positioneren van de koppen. Zodra de koppen eenmaal zijn geplaatst, kost het lezen van de platters relatief weinig tijd. Laagtoerige harde schijven, zoals de Seagate Barracuda Green in het testsysteem, hebben een gemiddelde toegangstijd van ongeveer 15 milliseconden en kunnen op de buitenste sporen lezen met een snelheid van 145MB/s. Het uitlezen van 64kB in plaats van 32kB kost bijvoorbeeld nog geen kwart milliseconde extra. Een test met een prefetch van 32kB leverde gemiddeld geen betere prestaties op dan met de standaardinstelling van 64kB.
Het aantal i/o's dat zfs tegelijkertijd naar de devices in een vdev stuurt, wordt beperkt door de tunable zfs_vdev_max_pending. Ook is er de zfs_vdev_min_pending-parameter, die het initiële aantal gelijktijdige i/o's bepaalt dat op een device uitstaat. De standaardwaarden van deze twee tunables zijn respectievelijk 10 en 4. In sommige dicussies over zfs-optimalisatie wordt geadviseerd om de waardes te verlagen voor betere responstijden. In onze benchmarks leverde een zfs_vdev_min_pending van 1 en een zfs_vdev_max_pending van 2 inderdaad betere resultaten op dan de standaardinstellingen.
In de onderstaande tabellen werden de resultaten met 64kB vdev prefetch uitgevoerd, met de standaardwaarden voor zfs_vdev_min_pending en zfs_vdev_max_pending. Vooral in de Data StorageMark 2011-index met diverse soorten file copy's en data-i/o van video- en beeldbewerking was er met acht procent een aanmerkelijk verschil ten opzichte van de standaardinstellingen. Storage pools die enkel uit ssd's bestaan, presteren waarschijnlijk wel beter met een hogere zfs_vdev_max_pending omdat ssd's een aantal geheugenkanalen tegelijkertijd kunnen gebruiken.
We hebben de tests op de komende pagina's uitgevoerd met een alignment van de storage pool op 4kB, een zvol-blokgrootte van 128kB, een vdev_min_pending van 1 en een vdev_max_pending van 2, de standaard vdev prefetch van 64kB en de standaard Comstar logical-unitsectorgrootte van 512 bytes.
Raid-level en aantal disks
Een vraag waar iedereen bij het bouwen van een opslagserver mee te maken krijgt, is welk raid-level bij welk aantal disks te gebruiken. Dat is een afweging tussen prestaties, betrouwbaarheid, opslagcapaciteit en uitbreidbaarheid. Zfs heeft op dit gebied andere eigenschappen dan hardwarematige raid-controllers.
Het ruimteverlies van raid-z en raid-z2 is gelijk aan dat van raid 5 en raid 6. Zfs verdeelt elk blok in een bestandssysteem of zvol echter over alle disks - behalve de parity disks - in een vdev. De random i/o-prestaties zijn dus beperkt tot het prestatieniveau van een enkele disk: alle disks zijn betrokken bij het lezen of schrijven van een enkel blok en kunnen zich dus niet met andere zaken bezighouden. Bij raid 5 en raid 6 kan dit wel, omdat een leestransfer kleiner dan de stripesize door een individuele disk afgehandeld kan worden. De sequentiële lees- en schrijfprestaties van een raid-z-, raid-z2- of raid-z3-vdev schalen wel mee met het aantal disks.
Vanwege de niet schalende random i/o-prestaties heeft het de voorkeur om raid-z-vdev's klein te houden. De random-i/o-prestaties kunnen dan verbeterd worden door een aantal kleine vdev's te stripen. Het beste raid-level voor random-i/o is raid 10, oftewel striping van mirrors.
Wat betreft de uitbreidbaarheid van storage pools moet er rekening worden gehouden met het feit dat het aantal disks in een vdev niet uitgebreid kan worden. Wel kunnen er extra vdev's aan een pool worden toegevoegd. Ook om deze reden is het aan te raden om kleine vdev's te gebruiken. Een pool met twee raid-z-vdev's van elk drie disks kan later uitgebreid worden met een derde vdev van drie disks.
Uitbreiding is het makkelijkst bij een pool die bestaat uit mirrors. In dat geval kan er per twee disks uitgebreid worden. Het is mogelijk om vdev's toe te voegen met een afwijkend raid-level of een afwijkende capaciteit ten opzichte van bestaande vdev's in een pool. De pool zal dan echter minder consistent presteren. Een bijkomend voordeel van kleine vdev's is de kortere rebuildtijd als er een disk in een vdev verloren gaat.
In de onderstaande tabel zijn een aantal voorbeelden van raidconfiguraties bij elkaar gezet. Hierbij is uitgegaan van Seagate Barracuda Green 5900.3-schijven die per stuk ongeveer 200 iops leveren. In de laatste kolom is de kans weergegeven dat het uitvallen van twee disks resulteert in dataverlies. Raid-z2 kan het falen van twee disks altijd opvangen. Dit is niet het geval bij raid 10 of een pool met meerdere raid-z-vdev's, maar de kans dat een tweede defect de reeds gedegradeerde vdev zal corrumperen is wel altijd lager dan 50 procent. Deze kans wordt bovendien kleiner naarmate het aantal vdev's toeneemt. Vooral voor grote harddiskpools zijn er veel configuraties met uiteenlopende prestaties, capaciteitsbenutting en bescherming mogelijk.
| Raid-level | Configuratie | Netto capaciteit | Random i/o | Kans op dataverlies
bij dubbele uitval |
| Vier disks |
| Raid-z |
3 + 1 |
6 TB |
200 iops |
100% |
| Raid-z2 |
2 + 2 |
4 TB |
200 iops |
0% |
| Raid 10 |
2x (1 + 1) |
4 TB |
400 iops |
33% (1 / 3) |
| Zes disks |
| Raid-z |
5 + 1 |
10 TB |
200 iops |
100% |
| Raid-z2 |
4 + 2 |
8 TB |
200 iops |
0% |
| Raid 10 |
3x (1 + 1) |
6 TB |
600 iops |
20% (1 / 5) |
| Raid-z10 |
2x (2 + 1) |
8 TB |
400 iops |
40% (2 / 5) |
| Acht disks |
| Raid-z |
7 + 1 |
14 TB |
200 iops |
100% |
| Raid-z2 |
6 + 2 |
12 TB |
200 iops |
0% |
| Raid 10 |
4x (1 + 1) |
8 TB |
800 iops |
14% (1 / 7) |
| Raid-z10 |
2x (3 + 1) |
12 TB |
400 iops |
43% (3 / 7) |
| Twaalf disks |
| Raid-z |
11 + 1 |
22 TB |
200 iops |
100% |
| Raid-z2 |
10 + 2 |
20 TB |
200 iops |
0% |
| Raid 10 |
6x (1 + 1) |
12 TB |
1200 iops |
9% (1 / 11) |
| Raid-z10 |
2x (5 + 1) |
20 TB |
400 iops |
45% (5 / 11) |
| Raid-z10 |
3x (3 + 1) |
18 TB |
600 iops |
27% (3 / 11) |
| Raid-z10 |
4x (2 + 1) |
16 TB |
800 iops |
18% (2 / 11) |
Om te kijken hoe de verschillende configuraties presteren hebben we de raid-levels raid-z, raid-z2 en raid 10 getest met vier, acht en twaalf disks. Ook hebben we raid-z10 getest met acht disks (twee vdev's) en twaalf disks (drie vdev's). Alle benchmarks werden uitgevoerd op de Windows-host en zijn dus resultaten die mogelijk zijn als een op zfs gebaseerde logical unit via fibre channel wordt benaderd. Als baselinevergelijking hebben we de prestaties van een enkele Seagate Barracuda Green in de grafieken opgenomen. Deze schijf werd rechtstreeks aan een sata-interface van het Windows-testsysteem aangesloten.
AS-SSD
In de 4K Random Read-test van AS-SSD halen bijna alle configuraties een doorvoer van rond de 27MBps. Verschillen zijn er wel in de 4K-random-read-test met 64 threads. Hier bereiken de configuraties met vier disks een doorvoer van 145 tot 165MBps, die oploopt naar 220 tot 270MBps bij twaalf disks. De verschillende raid-levels presteren nogal wisselend, hoewel de onderliggende verschillen niet groot zijn. Bij acht en twaalf disks is raid-z10 het snelst.
Vergeleken met de enkele lokale disk, die een doorvoer haalt van 0,6MB/s bij één thread en 1,9MB/s bij 64 threads, zijn de resultaten erg goed. Dit is waarschijnlijk te danken aan het copy-on-write-model van zfs, waardoor de willekeurige gegevens die AS-SSD inleest, daadwerkelijk willekeurig over de disks zijn verspreid. De hoge snelheden die zfs haalt in deze tests zien we normaal gesproken alleen bij ssd's.
In de 4K-random-write-test van AS-SSD zien we een wisselend beeld met resultaten die zich niet altijd eenvoudig laten verklaren. In de tests met een enkele thread levert raid 10 de beste prestaties bij acht en twaalf disks. Bij 64 threads worden er hogere snelheden geleverd door de raid-levels die de opslagcapaciteit van de pool beter benutten en naar meer verschillende fysieke drives kunnen schrijven.
Het uitzonderlijk hoge resultaat van raid-z met twaalf disks is waarschijnlijk een incident. Door de complexe variabelen die er in de achtergrond spelen, zoals automatische tuning van de omvang van caches en de duur van transactiegroepen, kunnen de prestaties van zfs erg wisselvallig zijn. Dankzij copy-on-write haalt zfs in ieder geval wel veel betere resultaten dan een 'dom' bestandssysteem dat direct tegen een disk praat.
IOMeter
De sequentiële doorvoersnelheden waren wisselvalliger. In IOMeter haalden we sterk uiteenlopende resultaten, afhankelijk van de transfergrootte en de queue depth. Bij een queue-depth van 1 was er bij een toename van het aantal disks geen enkele stijging in de doorvoersnelheid te zien. Ook maakte het raid-level geen noemenswaardig verschil. Dit was wel het geval bij een queue depth van 8. De hoogste doorvoersnelheden werden gehaald met een transfergrootte van 64K en een queue depth van 8. Een transfergrootte van 256K was langzamer dan 64K bij een queue-depth van 8, maar sneller bij een queue-depth van 1.
De prestaties van de raid-levels liepen sterk uiteen in de 64K- en 256K-tests. Raid 10 was het snelst in de 64K-tests en haalde met acht en twaalf disks respectabele doorvoersnelheden van 495 tot 555MBps. In de 256K-tests werden de beste resultaten neergezet door de raid-z10-configuratie, die met twaalf disks en drie vdev's een snelheid van 335MBps bereikte.
Trace-based benchmarks
De low-level benchmarks laten zien dat er in de meeste gevallen een gezonde stijging van de prestaties is te zien als het aantal disks toeneemt. Een duidelijk beeld over welk raid-level de beste prestaties biedt is er echter nog niet. De belangrijkste vraagt die we beantwoord willen hebben, is hoe de configuraties in de praktijk presteren. Daarom hebben we onze trace-based benchmarks op de zfs-machine losgelaten. De benchmarks worden uitgevoerd door Intels NAS Performance Toolkit en zijn gebaseerd op eigen traces van handelingen die veelvuldig in de praktijk voorkomen, zoals het booten van Windows, het starten van applicaties, het bewerken van foto's en video's en het kopiëren van bestanden.
De databewerkingstraces werden uitgevoerd op full speed, wat wil zeggen dat NAS Performance Toolkit direct een nieuwe transactie uitvoert zodra de vorige is voltooid. De overige traces werden uitgevoerd met behoud van originele timing. De rustpauzes in de oorspronkelijk trace werden wel wat gecomprimeerd om de duur van de tests te beperken, maar er bleef voldoende tijd over om bijvoorbeeld een write-back cache of zfs-transactiegroep de kans te geven om naar disk te synchroniseren, terwijl de gebruiker handelingen uitvoert die niet i/o-intensief zijn. De traces werden per set drie keer uitgevoerd. De set die werd uitgevoerd met de originele timing voerde 26,9GB aan leesoperaties uit en de full-speedset las 16,3GB. Vanwege de grote dataset was de invloed van de adaptive replacement cache op het testsysteem met 16GB ram gering.
Boot StorageMark 2011 laat de prestaties zien van een bootdrive waarop het besturingssysteem, applicaties en games zijn geïnstalleerd, en waarop een kleine hoeveelheid gebruikersdata aanwezig is. De benchmarks zijn relevant voor gebruikers die willen booten vanaf een storage area network, wat met fibre channel mogelijk is.
Het indexcijfer bestaat voor zestig procent uit de resultaten van twee traces van het booten van Windows 7 en het starten van veelgebruikte applicaties. De resultaten van de desktopworkload-trace worden voor 15 procent meegewogen. In deze trace worden webbrowsers, e-mailprogramma's, eenvoudige beeldbewerkingsprogramma's en kantoorapplicaties gebruikt. Twintig procent wordt bepaald door gametraces. De resterende 5 procent komt voor rekening van een trace waarin een groot softwarepakket wordt geïnstalleerd, terwijl er downloads plaatsvinden en lichte applicaties worden gedraaid, zoals een browser.
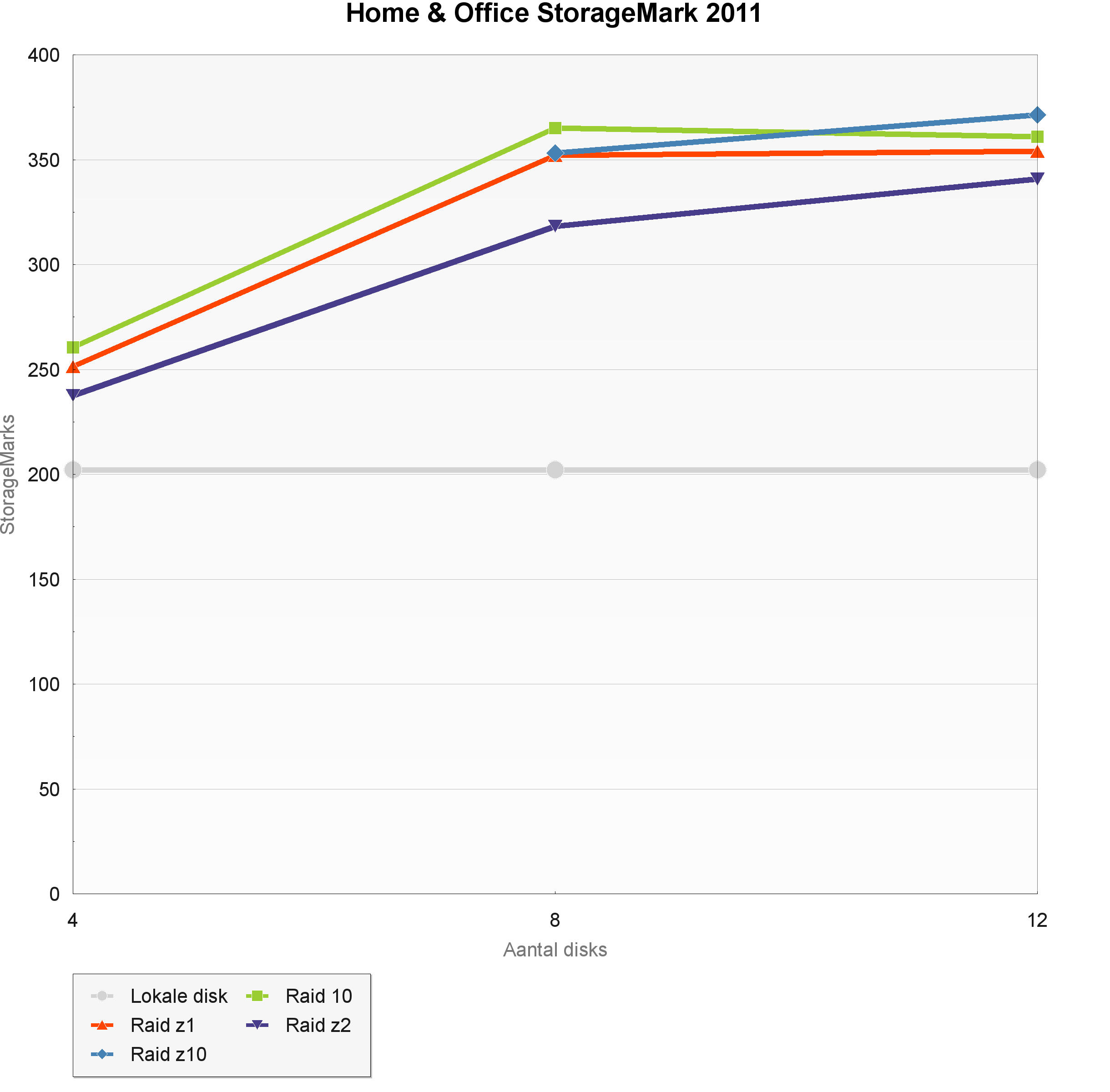
De traces in de bootindex doen vooral veel random leesoperaties met een lage queue-depth. Dit type i/o laat zich niet makkelijk verdelen over meerdere disks. De performance-scaling van vier naar acht disks is zwak, en tussen acht en twaalf disks is er zelfs bijna geen prestatiewinst meer te zien. Ook het verschil tussen de enkele lokale Barracuda Green en een zfs-volume met vier disks is gering. Raid 10 levert consequent de beste prestaties, gevolgd door raid-z10. Raid-z2 biedt mindere prestaties dan raid-z, zoals we hadden verwacht.

De Home & StorageMark 2011-index geeft een indicatie van het gebruik van een disk als primair opslagmedium voor OS, applicaties en data, in een systeem dat wordt ingezet voor kantoor- en webgebruik. De desktop-workload-trace is goed voor 60 procent van de index. Voor deze trace worden 90.000 lees- en 33.000 schrijfbewerkingen uitgevoerd, die voor de helft uit sequentiële bewerkingen bestaan. In de index zijn verder boot-, game-, kopieer- en software-installatietraces meegenomen.
De i/o in deze traces is vrij goed geschikt om verdeeld te worden over meerdere disks. De beste prestaties worden opnieuw geleverd door raid 10 en raid-z10 maar de prestatieverschillen tussen de raid-levels zijn gering. De stripe van mirrors levert tussen vier en acht disks een performanceverbetering van 40 procent, wat een stuk beter is dan de stijging van 17 procent in de bootindex. Er is opnieuw nauwelijks winst als het aantal disks wordt uitgebreid van acht naar twaalf.
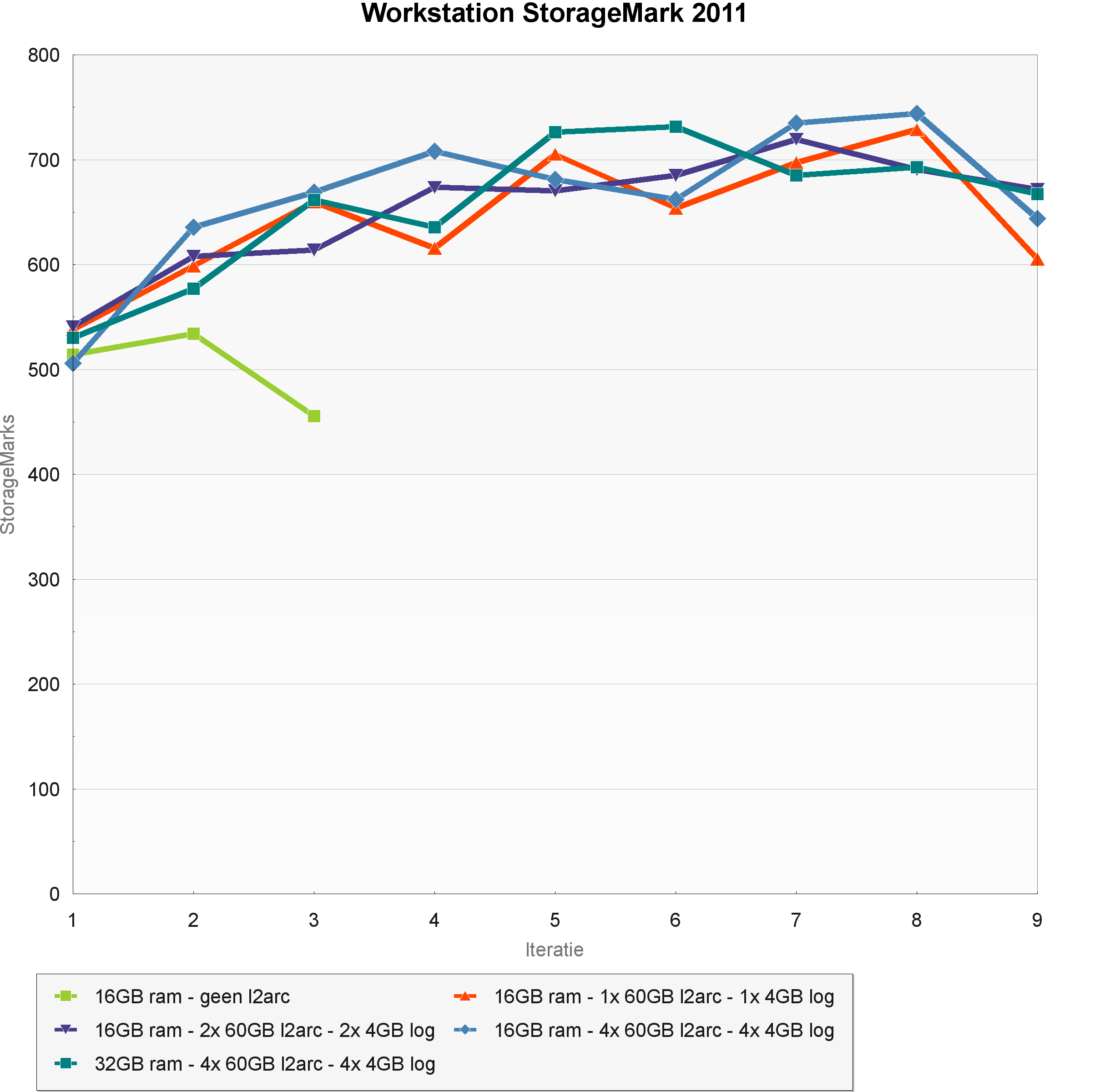
De Workstation StorageMark geeft een indruk van de prestaties van de primaire drive in een systeem voor professionele beeld- en videobewerkingssoftware. De index wordt voor 55 procent bepaald door twee traces van respectievelijk een grafisch workstation en een video-editingworkstation. Het zwaartepunt van deze benchmark wordt gevormd door 370.000 random leesacties en 250.000 random schrijfacties.
In de beeldbewerkingstrace wordt gewerkt aan zeer grote Photoshop-bestanden en worden fotocollecties met grote raw-bestanden bekeken en bewerkt in Lightroom. Deze trace bestaat voor 55 procent uit schrijftransacties. Als we naar het datavolume kijken komt zelfs tweederde van het verkeer voor rekening van schrijfacties. Het gaat daarbij overwegend om niet-sequentiële schrijfacties naar de scratchfile van Photoshop en de pagefile van Windows. Voor de videobewerkingstrace wordt Sony Vegas Pro losgelaten op een groot videoproject met tientallen lossless gecomprimeerde full-hd-videofragmenten. Deze trace bestaat bijna helemaal uit kleine en sterk verspreide leestransacties. Met een geringere weging maken ook de desktop-workload-, boot-, filecopy- en software-installatietraces deel uit van deze index.
De resultaten van de Workstation-benchmark komen in grote lijnen overeen met die van de Home & Office StorageMark 2011-test. Wel zijn de prestaties ten opzichte van een enkele lokale disk een stuk beter. Dit is waarschijnlijk te danken aan de slimme caching in zfs. De schrijfacties in de Photoshop-trace worden in het geheugen van de zfs-server opgevangen in vijf seconde durende transactiegroepen. Zolang er met korte bursts wordt geschreven, wat het geval is bij de schrijfacties naar de scratchfile van Photoshop, kan de transactiegroep met veel hogere snelheden inkomende data accepteren dan dat er naar disk kan worden gesynchroniseerd.

De Data StorageMark 2011 is gericht op het meten van de prestaties van hardware die louter wordt gebruikt voor de opslag van data. In de traces die deel uitmaken van deze index bevindt zich geen i/o van de pagefile, de scratchfile in Photoshop, applicatiebestanden of OS-bestanden. De index is samengesteld uit filecopy's in verschillende richtingen met uiteenlopende bestandsgroottes. Daarnaast bevat deze benchmark een bestandscompressietest en i/o van de datapartitie in de beeld- en videobewerkingstraces. Voor gebruikers die netwerkopslag alleen willen gebruiken om data te bewaren, en geen applicaties of het besturingssysteem zelf, is dit de belangrijkste index.
Ten opzichte van de eerdere indices zien we een veel betere performance-scaling tussen acht en twaalf drives. Raid 10 en raid-z10 leverend opnieuw de beste prestaties. De verschillen tussen de raid-levels zijn wat groter, vooral bij twaalf drives.

Om een indruk te geven van de serverprestaties hebben we ook de IOMeter-fileserversimulatie nog op de raidconfiguraties losgelaten. Deze simulatie genereert een kunstmatig toegangspatroon dat volledig uit random i/o's bestaat. De i/o's hebben een transfergrootte van 512 bytes tot 64kB en worden in een mix van 80 procent leesopdrachten en 20 procent schrijfopdrachten aan het opslagmedium aangeboden. Het toegangspatroon wordt uitgevoerd met een concurrency die oploopt van 1 tot 64 gelijktijdige i/o's. Het toegangspatroon geeft een indruk van de prestaties van een drive bij het uitvoeren van een mix van kleine gelijktijdige lees- en schrijfopdrachten.
De theorie over aantal iops van de verschillende raid-levels, zoals hierboven uitgedrukt in de tabel, lijkt in de praktijk grotendeels op te gaan. De raid-levels z1 en z2 leveren niet méér iops als het aantal disks groeit. Er is zelfs een negatieve performance-scaling zichtbaar. Raid 10 schaalt wel bijna lineair, hoewel de stijging in de praktijk veel minder groot is dan de theorie belooft: een verdubbeling van het aantal disks levert een winst van slechts 17 tot 26 procent op. Waarschijnlijk wordt een deel van de lees-i/o's uit de adative replacement cache geserveerd. Raid-z10 blijkt daadwerkelijk meer iops te leveren dan raid-z1 en -z2.

Uit onze benchmarks blijkt dat raid 10 over het algemeen de beste prestaties levert. In desktopachtige gebruiksscenario's zijn de verschillen met raid-z en raid-z2 beperkt en weegt het enorme verlies van bruikbare opslagcapaciteit in raid 10 niet op tegen de betere prestaties. Raid 10 is alleen aan te bevelen voor servertoepassingen die baat hebben bij een zo hoog mogelijk aantal iops.
Gebruikers die grote pools willen bouwen, doen er verstandig aan om verder te kijken dan de vanzelfsprekende raid-levels raid 10, raid-z1 en raid-z2. Het stripen van meerdere raid-z-vdev's biedt een goede middenweg tussen de prestaties van raid 10 en raid-z of -z2. De prestaties schalen beter dan die van een grote raid-z-pool. Als er met veel disks wordt gewerkt, is het beter om twee of meer raid-z-vdev's te stripen.
Een zogenaamde raid-z10 biedt minder bescherming dan raid-z2 maar kan bij grote pools wel dicht in de buurt komen. In een pool van twaalf disks met drie raid-z1-vdev's is de kans minder dan een derde dat een tweede defecte disk dezelfde vdev treft als de eerste defecte disk, en zo de hele pool laat omvallen.
Caching
Een van de sterke eigenschappen van zfs is de geavanceerde caching. Zfs ondersteunt read-caching op twee niveaus: de adaptive read cache of arc in het werkgeheugen en, optioneel, de level 2 arc of l2arc die snelle block devices zoals ssd's gebruikt. Write-caching wordt gedaan door asynchrone schrijfoperaties op te vangen in transactiegroepen, die met de standaardinstellingen een duur hebben van vijf seconden en maximaal een achtste van het werkgeheugen in beslag mogen nemen. De transactiegroepen worden om de vijf seconden gesynchroniseerd naar stabiele media. Burst writes kunnen zo sneller uitgevoerd worden dan met de snelheid van de onderliggende media. Synchrone schrijfoperaties kunnen versneld worden door ze in eerste instantie naar een log te schrijven op een device met lage schrijflatencies.
Write-caching
De werking van de transactiegroepen was in sommige gevallen duidelijk zichtbaar in de benchmarkresultaten: de doorvoersnelheden waren dan hoger dan die van de onderliggende disks. De resultaten zijn echter nogal wisselend. Zo hebben we enkele keren gezien dat filecopy-to-disk-trace met grote bestanden werd uitgevoerd met doorvoersnelheden van bijna 1,5GBps. De sequentiële schrijftest in AS-SSD liet zich vanwege zijn korte duur regelmatig foppen. Bij een sequentiële doorvoersnelheid van 145MBps per disk ligt de maximale schrijfsnelheid op 580MBps met acht disks in raid 10 en op 435MBps met vier disks in raid-z.
Het toevoegen van een logdevice aan de pool had geen groot effect op de prestaties. In de Workstationindex waren de resultaten van een pool met een 64GB Samsung 830-ssd als logdevice en een pool zonder logdevice nagenoeg gelijk. Verschillen waren er wel in de data-traces, waar de pool met logdevice ongeveer 5,5 procent sneller was dan die zonder.
Een blik op de i/o-statistieken van de pool leerde dat het logdevice nauwelijks werd gebruikt, en als er wel naar werd geschreven ging dat met doorvoersnelheden van hooguit enkele kilobytes per seconde. Er worden door ntfs blijkbaar nauwelijks synchrone schrijfoperaties gegenereerd.
Synchrone schrijfoperaties zijn er wel in overvloed als write caching in de Windows device manager wordt uitgezet. De schrijfprestaties van de disk storten dan in en ook een met logdevice zijn ze een stuk lager dan wanneer write caching wel is ingeschakeld. De synchrone schrijfacties die sporadisch voorkomen als write caching is ingeschakeld, lijken het gevolg van het beleid van Windows om de write-cache met enige regelmaat te flushen. Flushing kan uitgezet worden met de tweede checkbox in het onderstaande scherm.

De bovenstaande bevindingen zijn van toepassing op volumes waar het ntfs-bestandssysteem op wordt gedraaid. Het is denkbaar dat andere bestandssystemen afwijkende eigenschappen hebben met betrekking tot het inzetten van synchrone schrijfoperaties.
Read-caching
Voordat we aan de slag gingen met het testen van de adaptive replacement cache hebben we gekeken of de tunable l2arc_noprefetch = 0 een positieve invloed heeft op de prestaties. Deze variabele heeft standaard een waarde van 1 en zorgt dat de l2arc niet wordt gevuld met data uit de prefetch buffers. Als de l2arc relatief groot is in verhouding tot de dataset op de disk, kan het zinvol zijn om deze tunable op 0 te zetten zodat de l2arc sneller wordt gevuld. Onze tests met een l2arc van 64GB wees uit dat er geen noemswaardig verschil in prestaties was.
De invloed van de adaptive replacement cache hebben we getest door onze trace-based benchmarks net zo vaak te herhalen tot de prestaties niet meer verbeterden. Dit bleek uiteindelijk het geval na negen runs. De benchmarks werden wederom uitgevoerd in twee sets: de datatraces die op volle snelheid werden gedraaid en de overige traces die met behoud van de originele timing werden uitgevoerd. De twee sets zorgden voor respectievelijk 16GB en 27GB reads naar de pool. Voor aanvang van de eerste run van elke set werd de zfs-machine gereboot zodat er met lege caches werd begonnen.
Om te kijken welke invloed de hoeveelheid ram en het aantal cachedevices op de prestaties hebben, werden de benchmarks uitgevoerd in configuraties met 16GB ram en een, twee of vier Samsung 830 64GB-ssd's, en met 32GB ram en vier 64GB-ssd's. Omdat de dataset op een enkele ssd past, zullen prestatieverschillen tussen de configuraties met enerzijds een enkele en anderzijds twee of vier ssd's worden veroorzaakt door een sneller bruikbare cache of door striping van de cachedevices.
Van elke ssd werd 60GB capaciteit toegewezen aan de l2arc en 4GB aan de zfs intent log. Omdat zfs controle over het gehele device moet hebben om cache flushes te kunnen triggeren, is deze werkwijze niet aan te raden als er met bedrijfskritische gegevens wordt gewerkt. Voor thuisgebruikers is het echter de enige betaalbare manier om een logdevice in een pool te kunnen gebruiken. Het enige alternatief is immers om een dedicated ssd als logdevice te gebruiken - die vervolgens het grootste deel van de tijd niets doet, omdat er zelden synchrone writes plaatsvinden.
Op de vorige pagina hebben we kunnen zien dat de performance in de Boot StorageMark 2011-index zich niet makkelijk laat opschalen door het aantal disks in de pool te vergroten. Het toevoegen van een cachedevice levert wel een aanzienlijke prestatiewinst op. Als de cache na zeven runs is opgewarmd, zijn de resultaten bijna tweemaal zo goed als zonder de l2arc. Met twee en vier ssd's is de l2arc sneller nuttig, maar de uiteindelijke prestaties zijn niet beter dan met een enkel cachedevice. Hetzelfde geldt voor de verdubbeling van het geheugen naar 32GB.
Hoewel de pool dankzij de l2arc een stuk sneller wordt, zijn de prestaties nog niet op het niveau van een lokale ssd. Een inmiddels verouderde eerstegeneratie-Vertex haalt in de bootindex 600 punten terwijl de snelste ssd's van dit moment de grens van 1100 punten zijn gepasseerd.

In de Gaming StorageMark 2011-indices zien we een vergelijkbaar beeld als in de Bootindex, al is de prestatiewinst ten opzichte van de configuratie zonder l2arc hier nog groter. Het toevoegen van een cachedevice zorgt uiteindelijk voor een ruime verdubbeling van de prestaties; het aantal ssd's in de cache heeft weinig invloed op de prestaties. Meer geheugen zorgt ervoor dat meer gegevens sneller gecached kunnen worden, wat al in de tweede run rendement oplevert. Bij de volgende runs neemt het verschil ten opzichte van de 16GB-setup af naar vijf tot tien procent. Blijkbaar maakt het voor de prestaties niet zoveel uit of de data uit het geheugen of van een ssd komt.

In de traces uit de Home & Office StorageMark 2011-index vinden er naar verhouding meer schrijfacties plaats dan in de hierboven besproken Boot- en Gamingindices. Hier levert een cachedevice dus een 'kleinere' prestatiewinst van rond de 75 procent op. Behalve wat hogere pieken zorgen meer geheugen en een groter aantal ssd's niet voor overtuigend betere prestaties.

De resultaten van de Workstationindex worden voor bijna een derde bepaald door een beeldbewerkingstrace waarin zeer veel schrijfacties naar de scratchfile van Photoshop plaatsvinden. Deze trace profiteert slechts in geringe mate van read-caching door de l2arc. Vanwege de grote invloed van deze trace op de Workstationindex levert een cachedevice weer minder prestatiewinst op. Met l2arc worden er na het vullen van de caches nog ongeveer 50 procent betere prestaties gehaald. Het uiteindelijke prestatieniveau van ongeveer 700 punten bevindt zich nog onder het niveau van moderne budget-ssd's als de OCZ Agility 3 (850 punten) maar is al een stuk beter dan van oudere ssd's, zoals de OCZ Vertex 2 en de Intel X25-M (550 punten).
De Video Data Workload bevat de i/o van een datapartitie met videobestanden die werden gebruikt in een professioneel videobewerkingspakket. Omdat er bijna uitsluitend leesoperaties plaatsvinden, heeft deze trace veel baat bij grotere en snellere read caches. De 32GB-configuratie kon de gehele dataset in het werkgeheugen kwijt, wat zich vertaalde in een snel gevulde cache en aanzienlijk beter prestaties dan bij ssd-caching. Het effect van caching in ram is ook zichtbaar in de runs met 16GB ram en zonder l2arc. Het toevoegen van de l2arc zorgde ruwweg voor een verdubbeling van de prestaties; een upgrade van het geheugen naar 32GB verdubbelde de doorvoersnelheden nog een keer.

In Filecopy from Disk worden er bestanden gekopieerd vanaf de disk waarop de test wordt uitgevoerd. De leesacties vinden veel sneller plaats als de data door de adaptive replacement cache of diens secundaire broertje geserveerd kan worden. In de test met bestanden van gemiddelde grootte, zoals foto's, zorgt de l2arc voor een prestatieverbetering met bijna een factor drie. Het aantal ssd's in de l2arc maakt wederom weinig uit voor de prestaties. Meer ram zorgt vooral voor het sneller vullen van de cache, de maximale doorvoersnelheden worden hiermee niet veel beter.


Ten slotte hebben we de configuraties onderworpen aan de IOMeter-fileserversimulatie. Normaal gesproken voeren we die uit op een testbestand van 16GB. Om te voorkomen dat dit bestand grotendeels in ram gecached kon worden, werd er dit keer een testbestand van 64GB gebruikt. De fileserversimulatie wordt uitgevoerd met exponentioneel oplopende queue-depth van 1 tot 64 uitstaande i/o's. De concurrency van de i/o's is veel hoger dan die in de hierboven besproken gebruiksscenario's, die vooral voorkomen in desktop- en workstationomgevingen.
In de resultaten zien we voor het eerst een duidelijk verschil tussen een l2arc met één, twee of vier ssd's. Als de concurrency hoog genoeg is, worden de i/o's blijkbaar toch evenwichtig over de cachedevices verdeeld. Helaas neemt de performance-scaling bij meer dan twee ssd's sterk af. Ook is er weinig verschil tussen de configuratie met 16GB ram en vier ssd's en de opstelling met 32GB ram en vier ssd's.

We kunnen concluderen dat herhaalde leesoperaties op dezelfde gegevens een enorme boost krijgen van de adaptive replacement cache en de l2arc. Zodra er een voldoende grote l2arc aanwezig is, zorgt meer geheugen vooral voor het sneller vullen van de cache en niet zozeer voor betere prestaties.
In desktopworkloads is het niet zinvol om aan aantal kleine ssd's in plaats van een enkele ssd met dezelfde totale capaciteit te gebruiken; alleen workloads met een hoge concurrency profiteren hiervan. De cache-ssd moet vooral uitgezocht worden op basis van de verhouding tussen de capaciteit van de l2arc en de omvang van veelgebruikte gegevens in de dataset. Een grotere l2arc betekent uiteraard dat er meer data gecached kan worden en dat het vaker zal voorkomen dat data snel uit de l2arc gehaald kan worden. Op workloads waarbij de leesoperaties grotendeels door een snelle caching-ssd geserveerd kunnen worden, haalden we over het algemeen prestaties op het niveau van een wat oudere ssd.
In onze testopstelling, met een ntfs-bestandssysteem op een via Comstar geëxporteerd zvol, zorgde een logdevice niet voor een noemenswaardige prestatieverbetering. Het gebruik van een logdevice is alleen nuttig als er veel synchrone schrijfacties plaatsvinden.
Deduplicatie en compressie
Als laatste hebben we gekeken naar de impact van deduplicatie en compressie op de prestaties. De effectiviteit en de prestaties van beide ruimtebesparende technieken zijn vanzelfsprekend afhankelijk van de data waarmee gewerkt wordt. Met de benchmarks op deze pagina kunnen we een indruk geven van wat er mogelijk is.
In theorie bieden deduplicatie en compressie betere prestaties als de dataset bestaat uit veel redundante data of data die zich goed laat comprimeren. Deduplicatie ontdoet de dataset hierbij van blokken met een identieke inhoud, terwijl compressie de inhoud van de blokken zelf comprimeert. De tests vonden plaats met de maximum blokgrootte van 128K. Een kleinere blokgrootte zal er waarschijnlijk voor zorgen dat er meer blokken gededupliceerd kunnen worden, maar de overhead en het geheugengebruik zijn dan wel groter. Compressie werkt efficiënter op grote blokken.
AS-SSD
AS-SSD is een populaire benchmark voor solid state drives: het programma zou alleen oncomprimeerbare data wegschrijven. Sandforce-ssd's, die compressie en deduplicatie ondersteunen, kunnen zo getest worden in een worst-case scenario. Zfs haalde ondanks de geclaimde oncomprimeerbaarheid van de door AS-SSD gegenereerde data een compressieverhouding van 1,29x en een deduperatio van 2,28x.
Op de sequentiële leessnelheid hadden compressie en dedupe geen invloed. Door de korte testduur van AS-SSD kon de data rechtstreeks uit de adaptive replacement cache ingelezen worden, met een snelheid van ongeveer 1,1GBps. De random-readsnelheden werden wel beïnvloed door compressie en dedupe. In beide gevallen lagen de snelheden ongeveer een derde lager dan zonder toepassing van compressie of deduplicatie.
De sequentiële schrijfsnelheid was een flink stuk lager na het aanzetten van compressie of deduplicatie. Compressie verlaagde de doorvoer van 600MBps naar 273MBps. Met dedupe ingeschakeld bleef er 402MBps over.
De 4K random-writesnelheden werden bij het uitvoeren van een enkele thread nadelig beïnvloed door compressie en deduplicatie. Opvallend was dat compressie in de test met 64 threads juist veel betere resultaten mogelijk maakte. De i/o-statistieken van zpool iostat laten zien dat zfs bij het uitvoeren van kleine schrijfacties veel meer gegevens naar de pool wegschrijft dan er door de host worden gewijzigd. Het lijkt erop dat er elke host write van 4K resulteert in een schrijfactie ter grootte van de blokgrootte - in dit geval 128K - naar de pool. Compressie kan dit effect vermoedelijk weer rechtzetten als er gelijktijdige willekeurige schrijfacties plaatsvinden, zoals in de 4K random write-test met 64 threads.
Deduplicatie levert de slechtste prestaties op, ongeacht het aantal threads waarmee er naar het volume wordt geschreven. In de test met 64 threads is dedupe daardoor aanzienlijk trager dan de andere twee configuraties.
IOMeter
IOMeter werd uitgevoerd met de standaardinstelling om data met een repeterend gegevenspatroon te genereren. Dit patroon laat zich erg makkelijk comprimeren. Zfs slaagde erin om de weggeschreven data met een factor 27 te verkleinen. Dankzij de uitstekende compressieverhouding was de sequentiële schrijfsnelheid ruim 20 procent hoger dan van de configuratie zonder compressie en dedupe.
Hoewel het repeterende schrijfpatroon van IOMeter goed geschikt bleek voor compressie was er op blokniveau geen sprake van een herhalende inhoud. Deduplicatie slaagde er niet om de omvang van de dataset te verkleinen - maar reduceerde de doorvoersnelheid wel naar een vijfde van het oorspronkelijke niveau.
We hebben de test op een later tijdstip op een schone pool herhaald om de processorbelasting op de zfs-machine te meten. Met compressie werd er toen een doorvoer van 663MBps gehaald bij een processorbelasting van 64 procent. Dedupe was het zwaarst en belastte de vier cpu's in het testsysteem voor 86 procent terwijl er werd geschreven met een snelheid van 102MBps. Zonder dedupe en compressie werd er een transfer rate van 562MBps bereikt bij een processorbelasting van 74 procent.
Op data die makkelijk gecomprimeerd kan worden, zorgt compressie blijkbaar niet per definitie voor een hogere belasting van de cpu's. Deduplicatie vraagt wel om snelle cpu's. In alle gevallen werd de belasting evenwichtig verdeeld over de vier cores in het testsysteem. Een machine met meer cores en een hogere kloksnelheid zal waarschijnlijk betere deduplicatieprestaties neerzetten. Als duplicatie wordt toegepast, is het bovendien belangrijk om voor voldoende geheugen te zorgen, zodat de tabel met de checksums altijd in het ram past.
De onrealistische compressieratio van de gegevensstroom die IOMeter genereert, zorgt in het fileservertoegangspatroon voor een dikke verdubbeling van de prestaties. Het fileservertoegangspatroon bestaat voor 80 procent uit leesacties, wat gunstig is voor de compressieprestaties. Deduplicatie is op data zonder identieke blokken ongeveer een derde trager dan de configuratie zonder compressie en dedupe.
Trace-based benchmarks
Voor het uitvoeren van de trace-based benchmarks maken we gebruik van Intels NAS Performance Toolkit. Deze tool doet een poging om een willekeurig gegevenspatroon te genereren, waar echter toch veel herhaling in blijkt voor te komen. Deze data kon niet op blokniveau gecomprimeerd worden, maar het deduplicatieproces vond veel blokken met een identieke inhoud, resulterend in een twintigvoudige deduperatio.
De hoge deduperatio is verre van realistisch maar toonde wel aan dat deduplicatie voor betere prestaties kan zorgen als een workload grotendeels bestaat uit leesoperaties op blokken die een identieke inhoud hebben. In de Boot StorageMark 2011-test, waarin voornamelijk leesacties plaatsvinden, was deduplicatie 60 procent sneller dan de configuratie zonder compressie en dedupe. Compressie heeft geen nadelige gevolgen voor de prestaties als een workload bijna volledig uit leesacties bestaat.
In de Workstation StorageMark 2011-benchmark vindt een veel groter deel schrijfoperaties plaats. Compressie is hier een krappe tien procent in het nadeel ten opzichte van de configuratie zonder compressie en dedupe. Deduplicatie is ondanks het grotere aandeel schrijfacties nog steeds een kwart sneller. Deze voorsprong is geheel te danken aan de onrealistisch hoge deduperatio.
De nog grotere verhouding schrijfacties in de Data StorageMark 2011-index zorgt ervoor dat deduplicatie ondanks de hoge deduperatio slechtere prestaties levert dan de configuratie zonder compressie of dedupe. Compressie levert ongeveer een derde van de prestaties in. Ter vergelijking: in de filecopytests werden middelgrote bestanden met een snelheid van 280MBps naar de disk geschreven terwijl er op grote bestanden een schrijfdoorvoer van 310MBps werd gehaald. Dedupe deed respectievelijk 260MBps en 480MBps en de normale configuratie 490MBps en 670MBps. De doorvoersnelheden zijn in de Data StorageMark 2011-test dus nog meer dan redelijk.
Filecopytests
Omdat IOMeter en NAS Performance Toolkit geen data met realistische compressieverhoudingen kunnen genereren, hebben we een filecopytest uitgevoerd met logbestanden van Process Monitor. Logbestanden zijn een goed voorbeeld van gegevens die in de praktijk voorkomen, veel ruimte innemen en goed gecomprimeerd kunnen worden. De compressie van zfs slaagde erin om de logbestanden met bijna een factor drie te verkleinen. Dit ging wel ten koste van de schrijfsnelheden, die ongeveer 20 procent lager waren. Deduplicatie kon niets met de aangeboden data en bleef steken op een deduperatio van 1,0x. Daar moest een derde van de doorvoersnelheid voor ingeleverd worden.
| Filecopy to disk - Logbestanden |
| | Doorvoersnelheid in MB/s, hoger is beter |
| Geen compressie en dedupe |
**********
151 |
| Compressie |
********
125 |
| Deduplicatie |
********
114 |
De bovenstaande test werd vijf keer uitgevoerd, waarbij de logbestanden elke keer naar een andere directory werden gekopieerd. Vervolgens hebben we deze vijf directories vijf keer naar de pool gekopieerd. Hoewel er uiteindelijk tien keer dezelfde data naar de pool was geschreven, slaagde dedupe er nauwelijks in om identieke blokken te vinden. De deduperatio bereikte uiteindelijk een maximum van 1,15x. Blijkbaar werd de data telkens anders uitgelijnd ten opzichte van het begin van een blok. Dit is wellicht te voorkomen door een zvol dezelfde blokgrootte te geven als de clustergrootte van het gebruikte bestandssysteem, en het begin van het volume exact uit te lijnen op de grenzen van de blokken van het zvol. Onze test vond plaats met een zvol-blokgrootte van 128kB en de standaard ntfs-clustergrootte van 4kB.
De doorvoersnelheden lagen bij de kopieeropdracht op dezelfde disk veel hoger dan bij de eerdere kopieeractie, waarbij de bronbestanden zich op een ramdisk op de Windows-host bevonden. Ten opzichte van de normale configuratie presteerde het compressie-algoritme vergelijkbaar, maar dedupe was naar verhouding trager.
| Filecopy on disk - Logbestanden |
| | Doorvoersnelheid in MB/s, hoger is beter |
| Geen compressie en dedupe |
**********
638 |
| Compressie |
********
482 |
| Deduplicatie |
*****
304 |
Op basis van de bovenstaande benchmarks kunnen we concluderen dat compressie en deduplicatie in de meeste gevallen een nadelige invloed op de prestaties hebben. Compressie heeft een minder grote impact op de prestaties dan deduplicatie en zal in de praktijk waarschijnlijk het effectiefst zijn in het beperken van het ruimtegebruik. De invloed op de prestaties hangt onder andere af van de verhouding tussen lees- en schrijfoperaties; de invloed op de leesprestaties is beperkt. Het testsysteem met low-power harddisks in een raid-z1-configuratie met twee vdev's van vier disks haalde desondanks schrijftransferrates die hoger zijn dan de snelheid waarmee veel clients data kunnen aanbieden.
Het gebruik van compressie en deduplicatie heeft alleen zin als de opgeslagen data er geschikt voor is. Bij thuisgebruikers zal de meeste data bestaan uit foto's en films die al gecomprimeerd zijn. Deduplicatie is alleen geschikt voor specifieke toepassingen zoals backups en het opslaan van images voor virtuele machines. Bij dergelijke toepassingen is er op blokniveau meer redundantie in de opgeslagen gegevens te verwachten.
Conclusie
Het Zettabyte File System is uniek door de integratie van bestandssysteem en volumemanager, de goede bewaking van data-integriteit, de zelfreparerende eigenschappen, de ondersteuning van snapshots en deduplicatie, en de mogelijkheid om ssd's voor caching in te zetten. Zfs mag zich daarom met recht een van de meest geavanceerde bestandssystemen van dit moment noemen.
In combinatie met het Comstar-framework kunnen er eenvoudig scsi-targets opgezet worden die via diverse soorten interfaces, zoals ethernet, fibrechannel en serial attached scsi, toegankelijk gemaakt kunnen worden. Storage area networks zijn in het bedrijfsleven al langer onmisbaar, en op kleinere schaal kunnen ze ook in thuisnetwerken hun nut bewijzen. Door opslag te consolideren kunnen capaciteit en prestaties beter benut worden, en is het mogelijk om een stil en compact werkstation te bouwen dat toch toegang heeft tot vele terabytes aan storage.
Onze benchmarks wijzen uit dat een zfs-san prestaties kan halen die vergelijkbaar of beter zijn dan die van direct aangesloten harde schijven. Met behulp van low-power-harddisks, voldoende werkgeheugen en een snelle cache-ssd zijn er prestaties mogelijk op het niveau van eerstegeneratie-ssd's. Dat is een prima prestatie, zeker omdat de topologie van een storage area network veel complexer is dan die van direct aangesloten opslag, en omdat zfs zich met onder andere checksums meer werk op de hals haalt dan een normaal bestandssysteem.
Met het gebruik van ssd's voor read caching wordt een belangrijke beperking van normale raidsystemen op basis van harde schijven aangepakt. Die systemen presteren alleen beter met sequentiële of gelijktijdige i/o. Door de hoge toegangstijden van harde schijven schalen de prestaties slecht bij willekeurige transfers met een lage concurrency, zoals die bijvoorbeeld op bootdrives plaatsvinden. Ssd's excelleren in dergelijke workloads, en zfs kan de sterke eigenschappen van ssd's combineren met de lage kosten per gigabyte van harde schijven. De hardwarekosten zijn bovendien lager omdat zfs geen raid-controller nodig heeft. In systemen met veel disks kunnen er zo honderden euro's bespaard worden.
Het beheer van zfs via de command-line is goed te doen voor iedereen die basale kennis van unix-besturingssystemen heeft. Voor tweakers die de command-line eng vinden, zijn er webbased oplossingen zoals Napp-it en het Nexenta-besturingssysteem. Tweakers die een zfs-systeem willen bouwen en ervaring hebben met conventionele raid-controllers, zullen zich echter wel vertrouwd moeten maken met een aantal eigenaardigheden van zfs.
Zo is het bijvoorbeeld niet mogelijk om de capaciteit van een vdev in een storage pool uit te breiden. Dit kan alleen door extra vdev's toe te voegen, wat minimaal twee harde schijven per keer kost om een redundante vdev te maken. Omdat de inhoud van een blok altijd over alle harde schijven in een vdev wordt weggeschreven, schalen de random i/o-prestaties minder goed dan bij normale raid 5- en raid 6-arrays. De oplossing is om een pool uit meerdere vdev's op te bouwen. Deze kunnen dan wel weer onafhankelijk van elkaar aan verschillende lees- en schrijftransacties werken.
Hoewel de testresultaten in deze review bemoedigend zijn, moet gezegd dat de resultaten zijn verkregen met een veel snellere netwerkinterface dan de gigabit-ethernetverbinding die de meeste tweakers hebben liggen. De vierpoorts 4Gbps-fibrechannel-adapters die we voor onze tests gebruikten, kunnen samen met de benodigde optische kabels op eBay bij elkaar gescharreld worden voor rond de vijfhonderd euro. Dat is veel geld om een snelle brug tussen twee systemen te bouwen. Om de vier poorten tegelijkertijd te gebruiken is er bovendien een besturingssysteem nodig met ondersteuning voor multipath-i/o. Die ondersteuning is er in onder andere Linux, OS X Lion en Windows Server 2008, maar is door Microsoft in Windows 7 weggelaten.
Er is een betaalbaardere oplossing om de gigabit-barrière te doorbreken: infiniband. Voor 200 euro is het mogelijk om twee dual-port 10Gbps-infiniband-adapters met bijbehorende kabels op de kop te tikken. Zonder multipath-i/o bieden die al een theoretische doorvoer van ongeveer een gigabyte per seconde. In het vervolg op dit artikel zullen we onderzoeken hoe gigabit-ethernet, fibrechannel en infiniband ten opzichte van elkaar presteren.


/i/1330094863.png?f=imagegallery "NexentaStor screenshot")

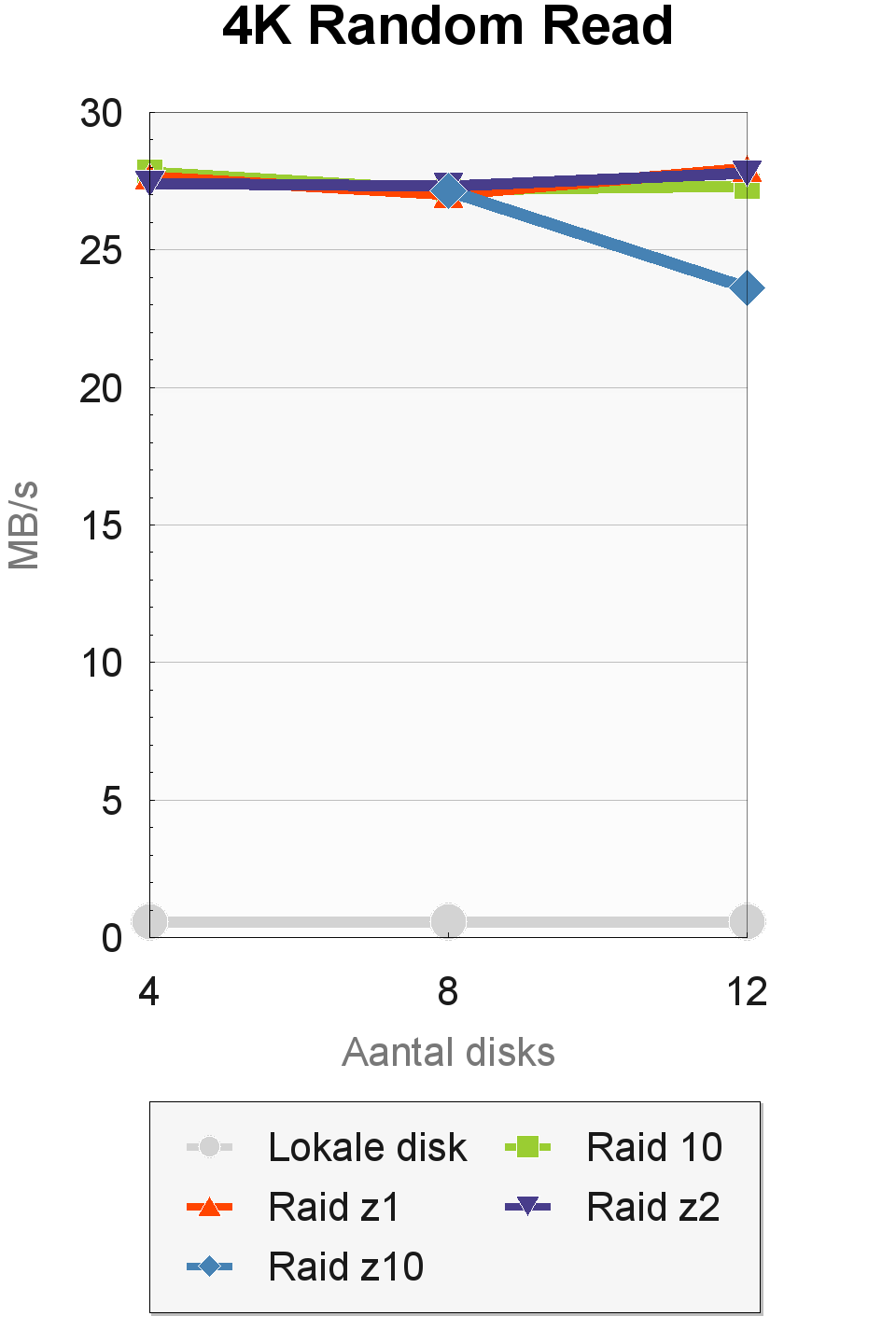
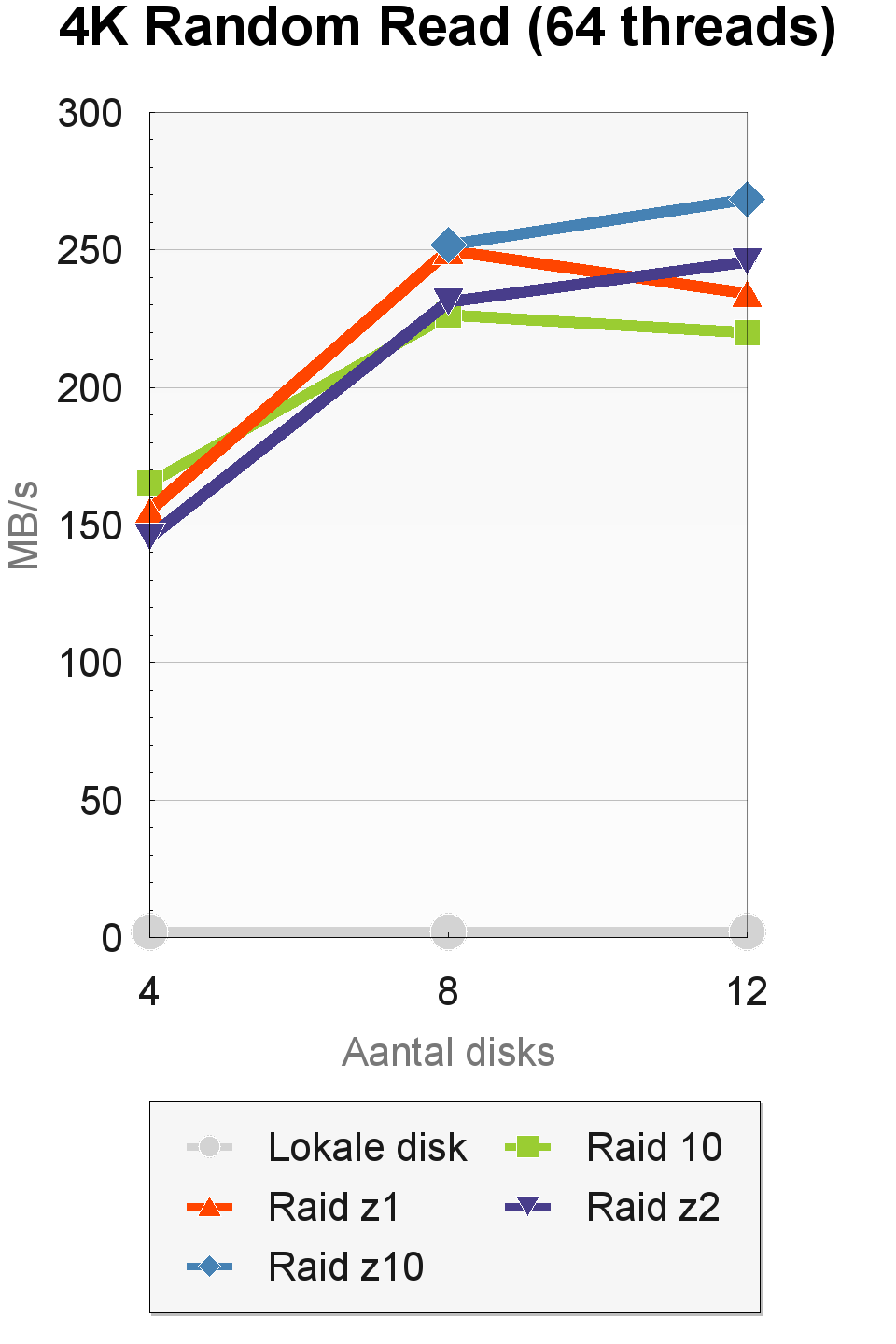
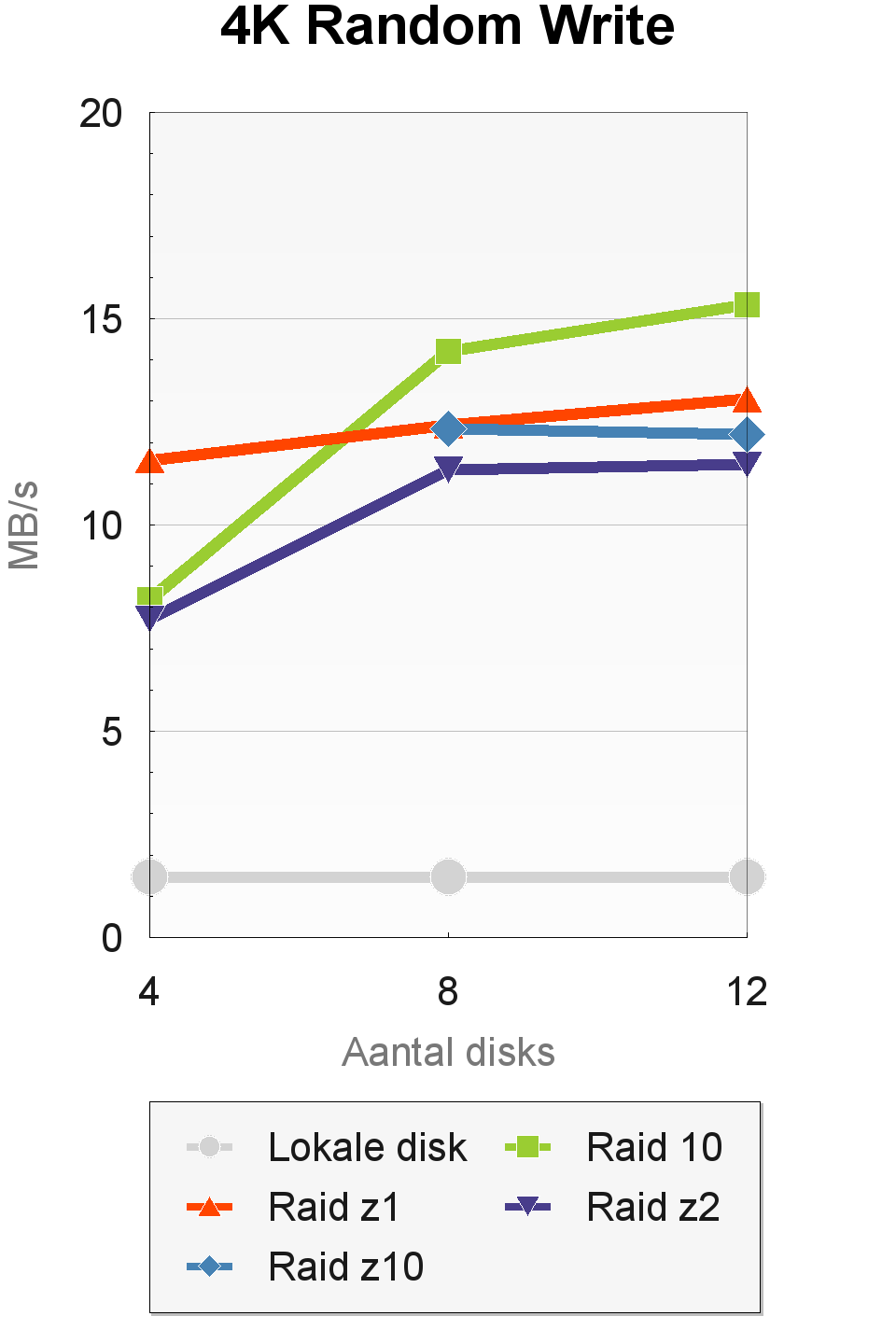
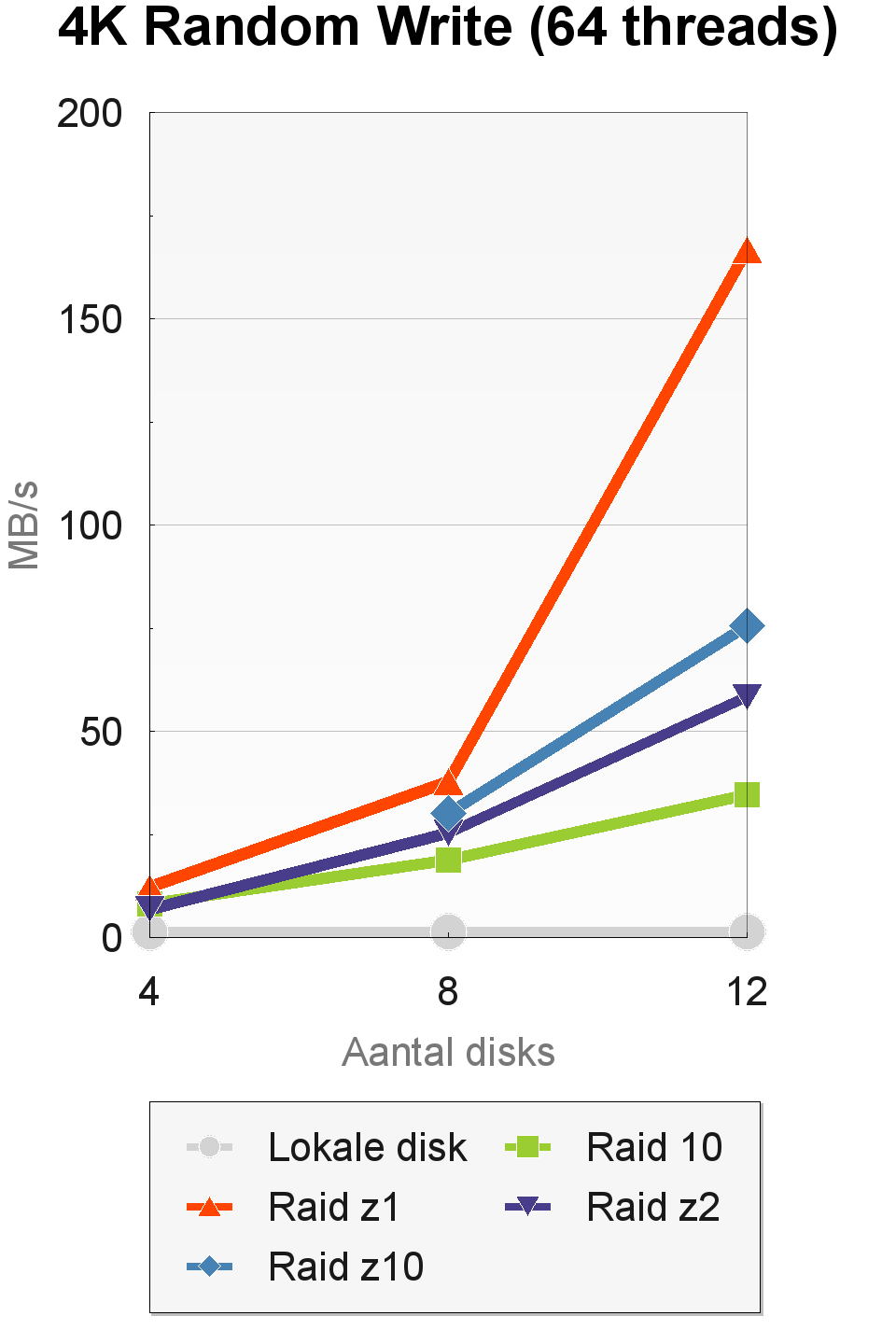
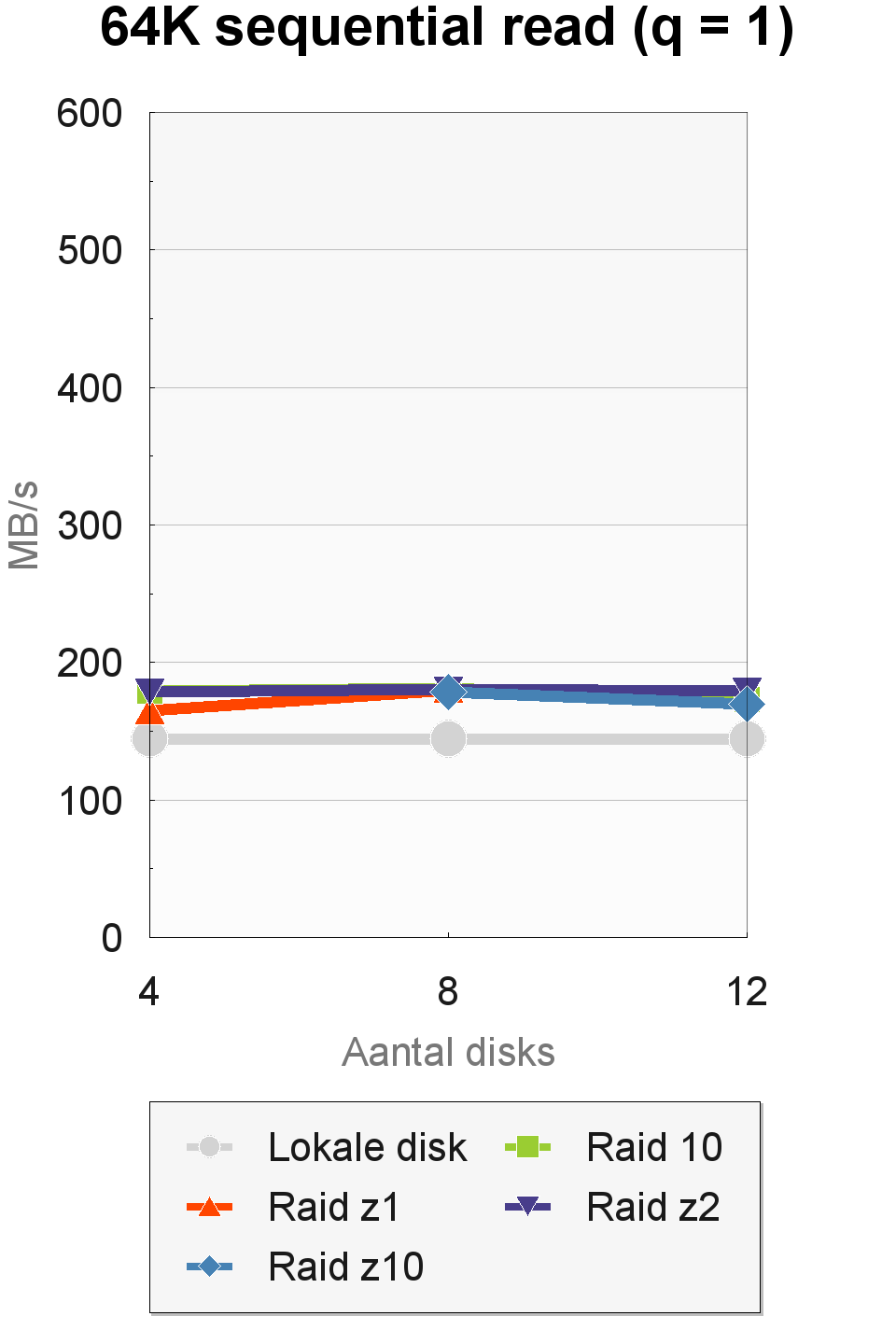
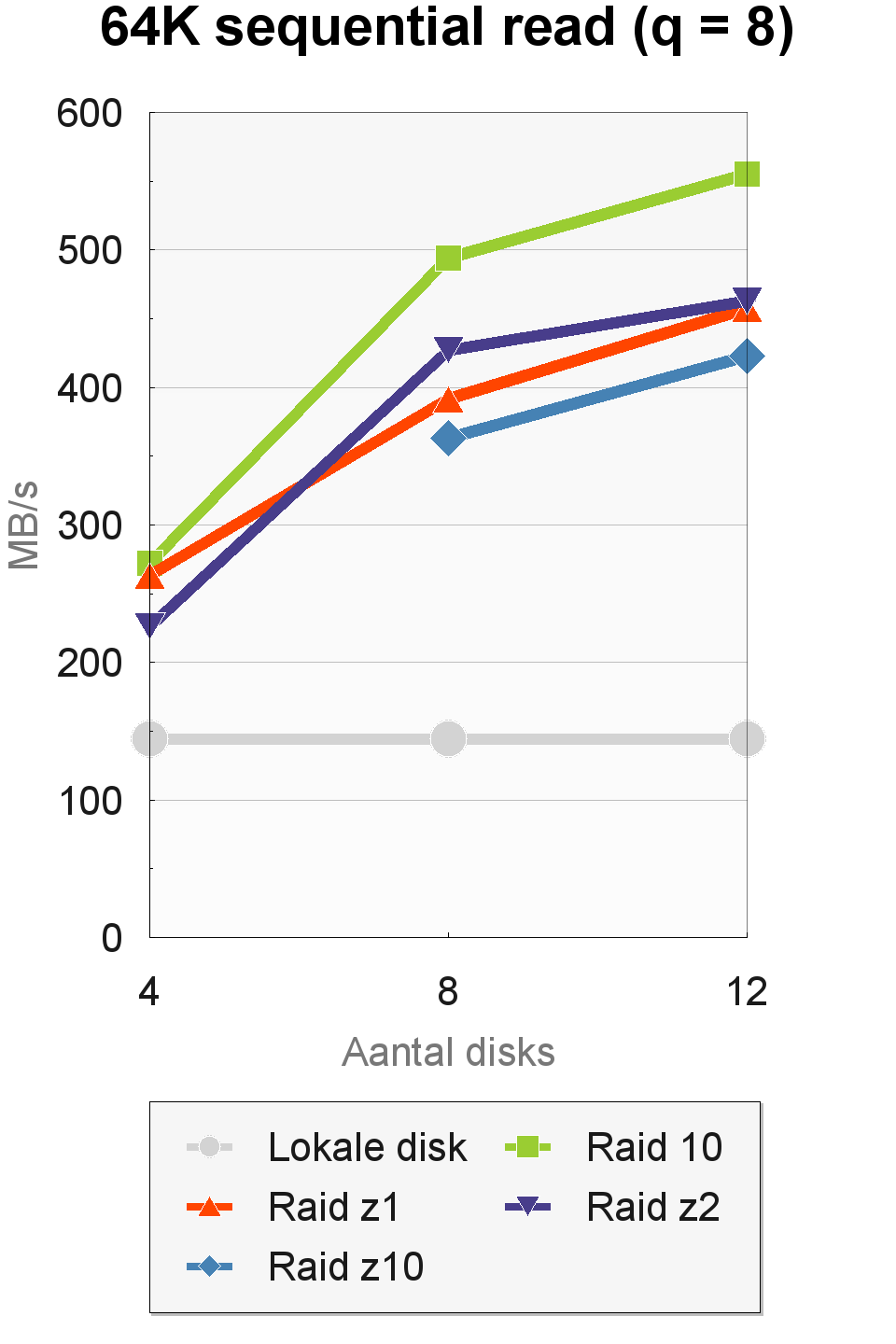
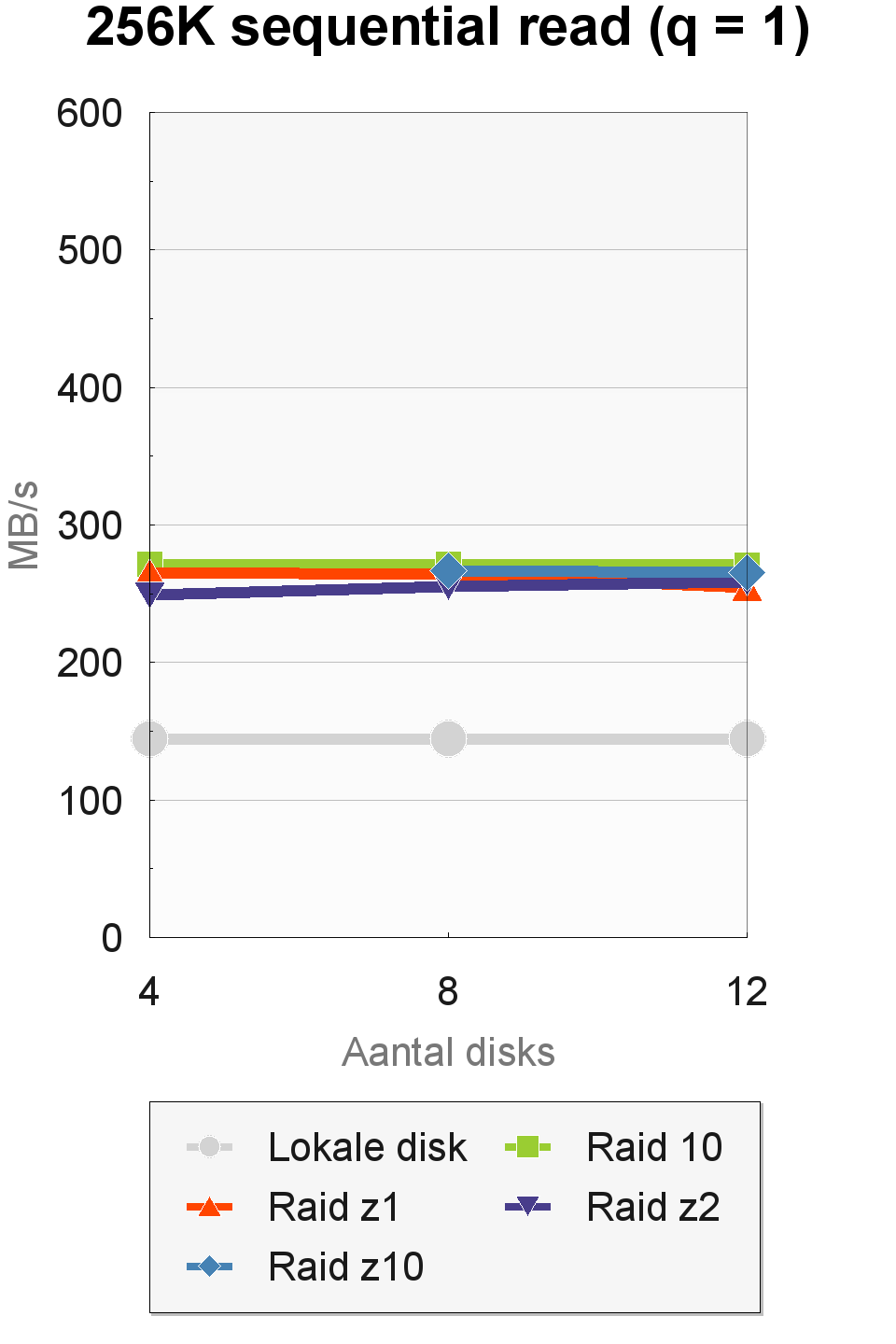
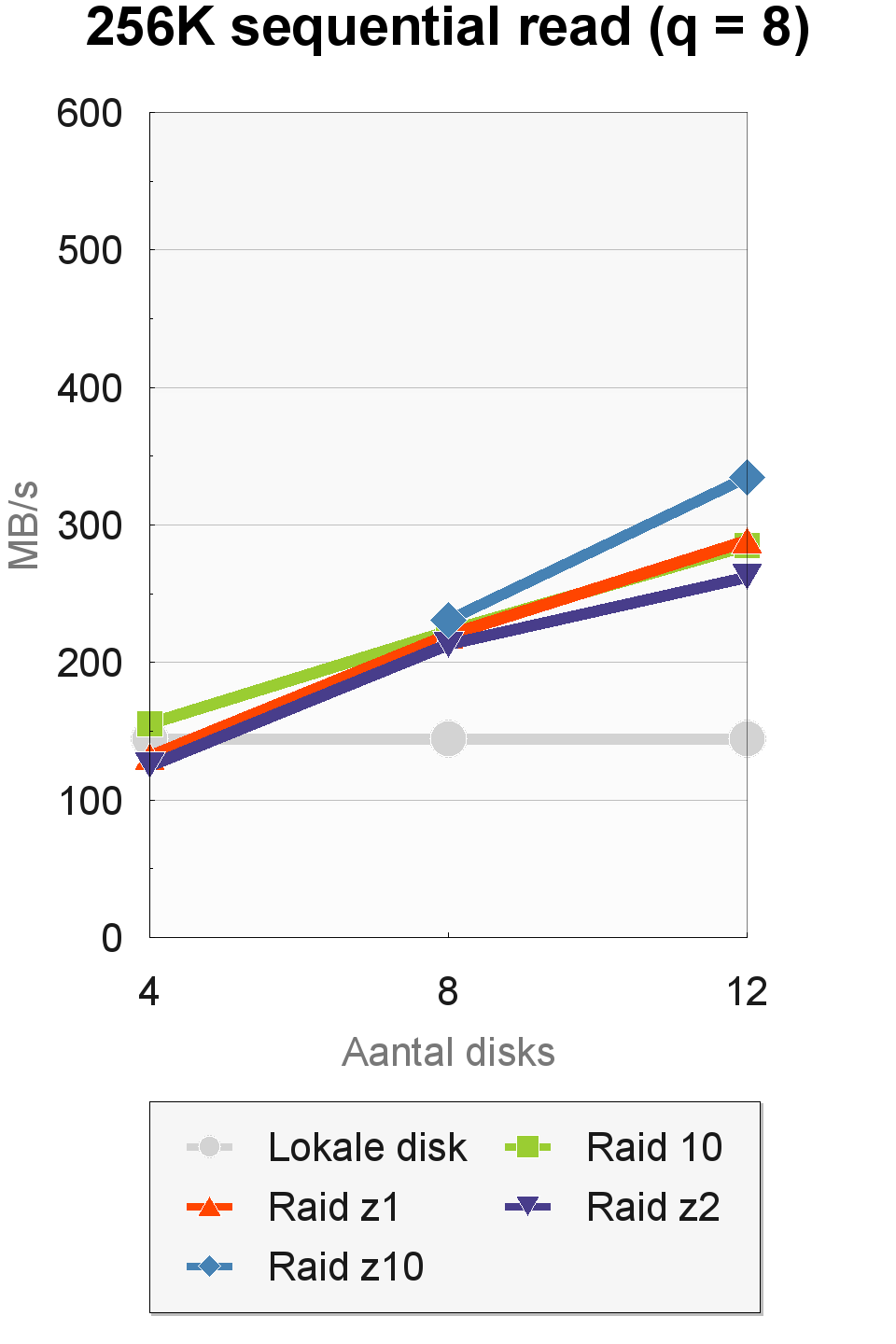
:fill(white):strip_exif()/i/1291369664.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/1298026594.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/1317386828.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/1315556894.jpeg?f=thumbmedium)
/u/351515/crop6897f6e5d19a1_cropped.png?f=community)
/u/444038/ek.png?f=community)
:fill(white):strip_exif()/i/1330045312.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/1319627057.jpeg?f=thumbmedium)
:strip_icc():strip_exif()/u/75893/crop6829f1faf0987_cropped.jpg?f=community)
/u/8/oog3.png?f=community)
/u/1/femme.png?f=community)
:strip_exif()/u/16970/crop57cd1ef1eb0d0.gif?f=community)
:strip_icc():strip_exif()/u/245037/Intel.jpg?f=community)
/u/80078/iconiPad.png?f=community)
:strip_icc():strip_exif()/u/312250/crop58172eb91ebc5_cropped.jpeg?f=community)
/u/93683/hadoop_med.png?f=community)
:strip_icc():strip_exif()/u/370910/Ubuntu2.jpg?f=community)