Het Chinese DeepSeek heeft zijn V4-taalmodellen onthuld. Deze zouden vooral beter zijn in programmeren, redeneren en agentische taken. Het zijn naar verluidt de eerste modellen van de fabrikant die zijn getraind op Chinese hardware.
DeepSeek heeft de V4-modellen als preview beschikbaar gemaakt op Hugging Face. Het V4-pro-model heeft 1,6 biljoen parameters, waarmee het het grootste model is dat DeepSeek tot dusver heeft ontwikkeld. Het kleinere V4-flash-model telt 284 miljard parameters. Beide modellen hebben een contextvenster van 1 miljoen tokens, terwijl het vorige model een contextvenster van 128.000 tokens heeft.
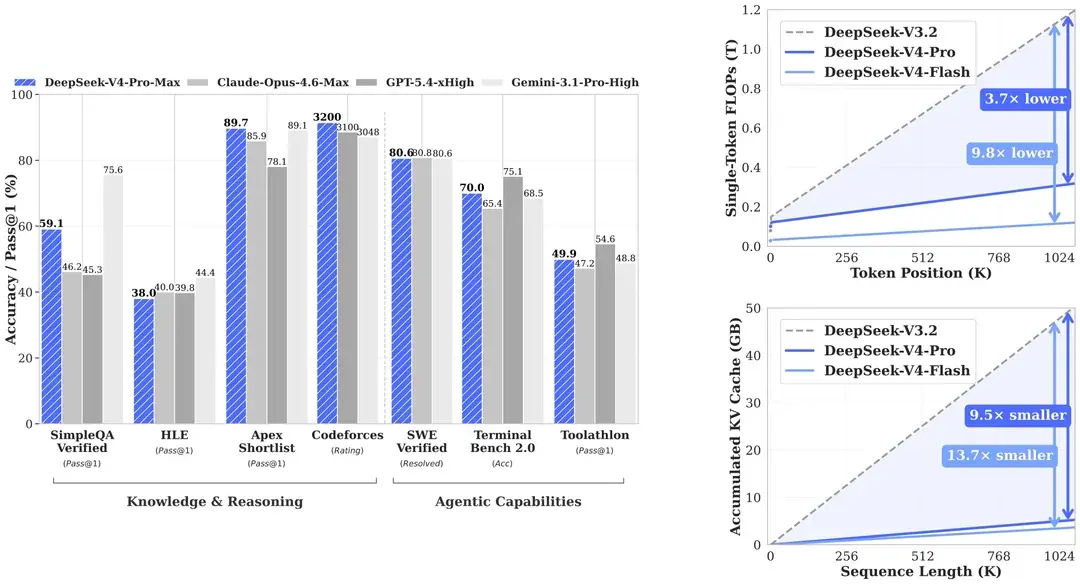
DeepSeek claimt dat V4-pro op het gebied van wereldkennis, redeneren, programmeren en agentische taken significant beter scoort dan zijn V3-modellen. Ook zou het model in veel benchmarks, zoals SimpleQA en Codeforces, beter presteren dan concurrerende modellen als GPT-5.4 en Claude Opus 4.6, hoewel Gemini 3.1 Pro High meestal hogere scores behaalt. Net als de andere llm's van DeepSeek maken de V4-modellen gebruik van het 'openweightprincipe', wat betekent dat de parameters van de modellen door gebruikers aangepast mogen worden. De llm's zelf worden onder een MIT-opensourcelicentie ontwikkeld.
The Information schreef eerder dat het V4-model is getraind op Huawei-gpu's, terwijl vorige versies afhankelijk waren van Nvidia-hardware. De Nvidia-chips die DeepSeek daarbij gebruikte, vallen mogelijk onder de Amerikaanse exportbeperkingen. De Chinese fabrikant vermeldt niet op welke chips het nieuwe model is getraind. Wel bevestigt Huawei dat het nauw heeft samengewerkt met DeepSeek om ervoor te zorgen dat zijn Ascend-hardware het nieuwe taalmodel 'ondersteunt'.

:strip_exif()/i/2007212562.jpeg?f=fpa)
/i/2006829312.png?f=fpa)
:strip_exif()/i/2006573404.jpeg?f=fpa)
/u/27299/hoofd.png?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
:strip_icc():strip_exif()/u/650993/crop5e187bafe012e_cropped.jpeg?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
:strip_icc():strip_exif()/u/572004/fox.jpg?f=community)
:strip_icc():strip_exif()/u/99162/crop5fbeb65712858_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/136442/crop6198f3130240d.jpg?f=community)
/u/654175/crop5628bfffe5fdf_cropped.png?f=community)
:strip_exif()/u/35573/0sm.gif?f=community)
:strip_icc():strip_exif()/u/76569/garfield14.jpg?f=community)
{kind=link}
{kind=link}