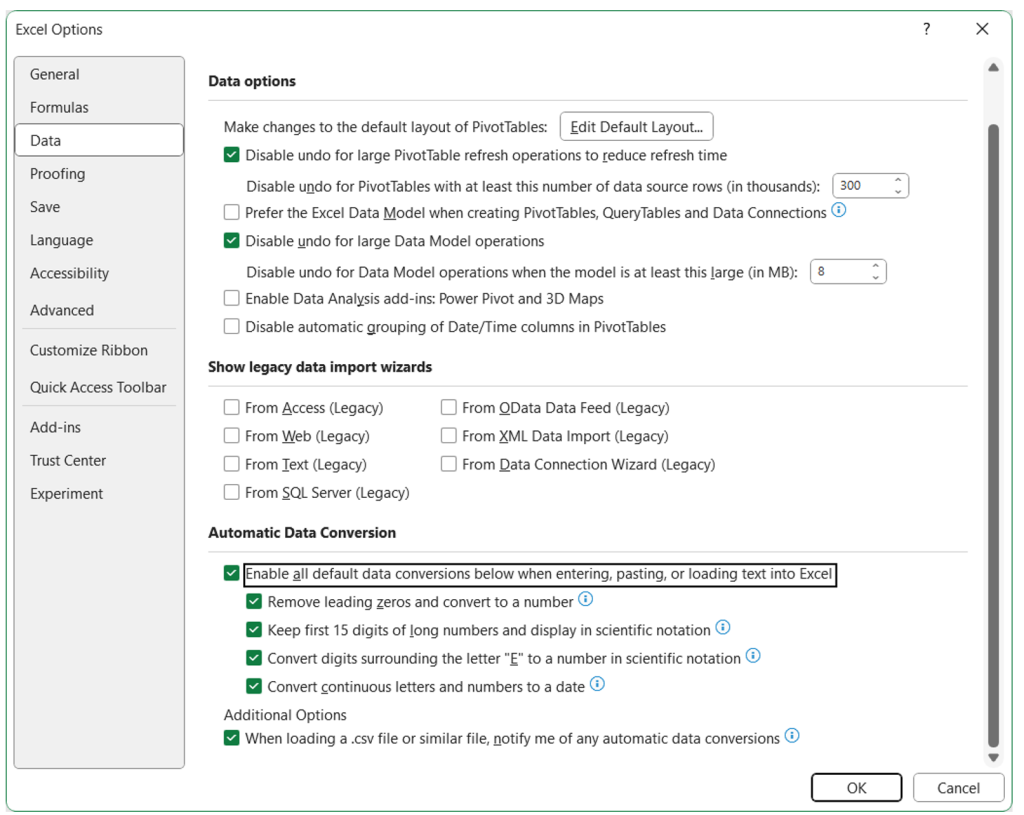
Microsoft heeft de werking van de Excel-functie voor automatische conversie aangepast, zodat het niet automatisch namen van genen omzet naar data. De namen van de genen waren al aangepast, omdat Excel ze bleef zien als data.
De fix is afgelopen week beschikbaar gemaakt, meldt een Microsoft-engineer die aan Excel werkt. De fix zorgt ervoor dat er opties zijn voor de verschillende soorten conversie van data in Excel, waardoor gebruikers die ergens tegenaan lopen specifieke vormen van conversie kunnen uitzetten.
De fix komt jaren nadat wetenschappers hebben aangegeven dat het bij het invoeren van genen fout gaat in Excel. Ongeveer 3,5 jaar geleden wijzigden de wetenschappers van Human Gene Nomenclature Committee de namen van sommige genen om verwarring met data in Excel te voorkomen. Daarbij ging het onder meer om Membrane Associated Ring-CH-Type Finger 1, dat tot voor kort MARCH1 heette. Excel zette dat automatisch om in '1 maart' en wetenschappers die dat programma gebruiken, moeten dat dus elke keer ongedaan maken. Er was geen manier om te voorkomen dat Excel dat doet. MARCH1 heet nu MARCHF1 en SEPT1 heet sindsdien SEPTIN1

:fill(white):strip_exif()/i/1306408850.jpeg?f=thumbmedium)
:strip_exif()/i/2003056170.jpeg?f=fpa)
:strip_icc():strip_exif()/u/969809/crop5e5cf5ef26cc8_cropped.jpeg?f=community)
:strip_exif()/u/109857/ico2.gif?f=community)
:strip_exif()/u/106005/animated%2520garfield.gif?f=community)
:strip_icc():strip_exif()/u/868355/crop602e22713116a_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/532382/crop61ac90e7248e0_cropped.jpg?f=community)
/u/314906/crop68a5aa8bdd674_cropped.png?f=community)
:strip_icc():strip_exif()/u/270072/crop600be8fca1d4a.jpeg?f=community)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
/u/11437/wandcontactdoos.png?f=community)
:strip_icc():strip_exif()/u/69284/crop57e50be3c39f4_cropped.jpeg?f=community)
/u/152928/crop5f2a6769d94ac.png?f=community)
:strip_icc():strip_exif()/u/149215/maillist.jpg?f=community)
:strip_exif()/u/87336/crop6891d2e354b09.gif?f=community)
/u/287626/crop62f1188ea6b19_cropped.png?f=community)
/u/141669/av.JPG?f=community)
/u/649844/crop5f804331d9657_cropped.png?f=community)
/u/1628798/crop60c3c9f67e0d5_cropped.png?f=community)