De eerste systemen met Intels Knights Landing Xeon Phi-accelerator komen in het eerste kwartaal van 2016 beschikbaar. Dat heeft de fabrikant bekendgemaakt tijdens de introductie van Intels Scalable System Framework voor high performance computing.
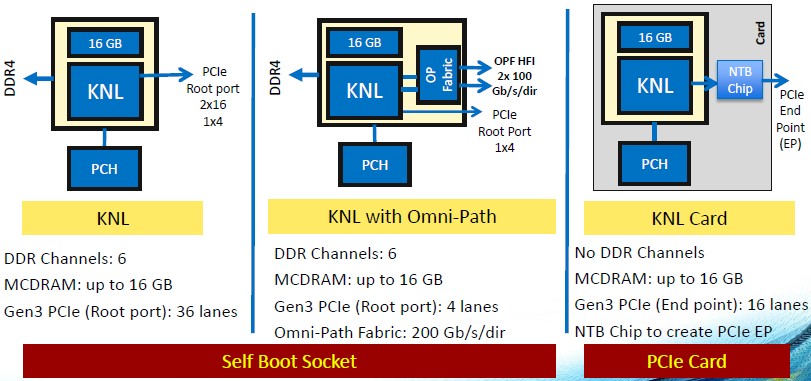
Intel is momenteel bezig met de voorbereidingen van de introductie van de Knights Landing Xeon Phi-kaart en inmiddels draaien bij de eerste partners, waaronder Cray, preproductiemodellen van de accelerator, maakte het bedrijf bekend. De opvolger van Knights Corner wordt op 14nm geproduceerd, bevat 72 cores en wordt voorzien van 16GB multi channel dram. Dit type geheugen zou een doorvoersnelheid van 400GB/s kunnen behalen. Knights Landing heeft verder ondersteuning voor 36 pci-e 3.0-lanes en voor de Omni-Path Architecture.
Deze architectuur maakt deel uit van Intels Scalable System Framework voor high performance computing. Omni-Path is Intels poging een alternatief voor InfiniBand te bieden met lage latency en hoge bandbreedte. InfiniBand heeft zijn langste tijd gehad, claimt Intel, en Omni-Path moet met zijn bandbreedte van 100Gbit/s en latency van 100 tot 110ns per poort beter op de toekomst voorbereid zijn. Intel introduceert een switch-chip met 48 poorten als basis voor de Omni-Path-architectuur. Bij InfiniBand zou het maximum op 36 poorten liggen. Onder andere Cray, Dell, Fujitsu, Lenovo en SuperMicro maken al gebruik van de Omni-Path Architecture.
/i/2000847583.png?f=imagegallery)
:strip_exif()/i/2000847584.jpeg?f=imagegallery)

:strip_exif()/i/2000847586.jpeg?f=imagegallery)
:fill(black)/i/2000847581.jpeg?f=imagegallery)

:fill(white):strip_exif()/i/2000573149.jpeg?f=thumbmedium)
:fill(white):strip_exif()/i/2000571060.jpeg?f=thumbmedium)
/i/1242207182.png?f=fpa)
/i/1309767168.png?f=fpa)
/i/1325597952.png?f=fpa)
/i/1226912359.png?f=fpa)
/i/1340056824.png?f=fpa)
/i/1370069782.png?f=fpa)
/u/349199/crop69f59caff1e30_cropped.png?f=community)
:strip_exif()/u/16366/NeXTLogo-av.gif?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/26020/senna_small.jpg?f=community)
:strip_icc():strip_exif()/u/53639/iconstar.jpg?f=community)
/u/408603/awsme0.png?f=community)
:strip_exif()/u/192051/crop57c43b80a7003_cropped.gif?f=community)
:strip_icc():strip_exif()/u/127657/crop6246f27e8175c.jpg?f=community)
:strip_icc():strip_exif()/u/174878/SCKnightMicro.jpg?f=community)
{kind=link}