De eerste hostingstapjes
Tweakers.net is niet altijd zo groot en financieel gezond geweest als vandaag de dag. Begin 2001 werden Tweakers.net en Fok nog samen bij Vuurwerk Internet gehost om de kosten een beetje te drukken. Al snel bleek dat ook die serverinrichting niet optimaal was.
Artemis was in december 2000 net geplaatst en snorde lekker mee in het cluster met webservers Athena en Aphrodite. De werklast werd erg simpel verdeeld door het draaien van afzonderlijke onderdelen op een server.
:fill(black)/i/983338015.jpg?f=thumb)
/i/983339430.jpg?f=thumb)
:fill(black)/i/983338156.jpg?f=thumb)
:fill(black)/i/983337566.jpg?f=thumb)
De eerste drie servers in het rackNa de ingebruikname van de nieuwe databaseserver bleek dat ook deze configuratie niet krachtig genoeg was om de inmiddels vele duizenden Tweakers elke dag te voorzien van hun portie tweakotine. Er werden dus meteen plannen gemaakt om nieuwe webservers in het rack te plaatsen en bestaande configuraties aan te passen.
Vooral de databaseserver had een upgrade nodig; de scsi-raidcontroller in die server werkte niet onder Linux en daarom werd er Freebsd op gedraaid. Na plaatsing in het rack kwamen we erachter dat Freebsd slechts één core gebruikte en niet beide. Hoewel dat in eerste instantie geen probleem was, is, toen de load op de database te hoog werd, besloten om er meerdere Mysql-processen op te gaan draaien. Dit had echter een behoorlijk negatieve invloed op de stabiliteit van Mysql, zodat we op sommige dagen Mysql een aantal keren moesten herstarten. De hele server had in die dagen een paar keer per week een schop nodig. Om dit op te lossen zouden er een nieuwe raidcontroller en een tweetal krachtigere processors in Artemis worden geplaatst, en zou het OS omgezet worden naar Linux.

De situatie zoals we die in gedachten haddenOp 13 maart werd begonnen met het uitvoeren van deze plannen. Serverbeheerder Rick had de twee nieuwe webservers Odin en Arshia, vernoemd naar de Noorse God en de toenmalige vriendin van Rick, voorzien van een Freebsd-installatie. De nieuwe servers waren voorzien van een 1GHz en een 1,2GHz AMD Thunderbird. Samen met 512MB geheugen en een 15GB of een 20GB harde schijf werden ze in een 2U Procase-behuizing geplaatst. Deze webservers werden bij Vuurwerk neergezet. In eerste instantie was het ook de bedoeling om de databaseserver te voorzien van een nieuwe raidcontroller en een nieuw OS, maar bij Vuurwerk mochten we alleen woensdagmiddag een uurtje met de servers spelen, wat niet genoeg tijd is om een server grondig te verbouwen. Wel werden de twee 733MHz PIII Intel-processors vervangen door twee snellere 1GHz PIII-processors. Een maand later werd ook de voeding vervangen zodat Artemis deze nieuwe processors ook volledig kon gebruiken. Het tweetal bracht het totaal aantal servers in ons park op vijf.
:fill(black)/i/984602841.jpg?f=thumb)
:fill(black)/i/984602474.jpg?f=thumb)
:fill(black)/i/984602590.jpg?f=thumb)
:fill(black)/i/984602294.jpg?f=thumb)
Twee nieuwe webserver in het rack & een state of the art switchIn die tijd werd ook op het personele vlak een aantal veranderingen doorgevoerd: Rick Jansen gaf aan dat hij in de zomer ermee ging stoppen en begin april 2001 vroeg hij Kees Hoekzema om het stokje van hem over te nemen als nieuwe bofh.
Big Crash 3
 De voorbereiding
De voorbereiding
Omdat het serverpark nog niet geheel naar wens liep en noodzakelijke upgrades aan Artemis door tijdgebrek niet door waren gegaan, was downtime in die periode een bekend probleem. Daarom werd besloten het serverpark nogmaals uit te breiden en bestaande configuraties aan te passen. Zo moest er in Artemis een scsi-kabel worden vervangen omdat een connector niet op een geheel juiste wijze behandeld was en hierdoor niet meer gebruikt kon worden om meer scsi-schijven aan te sluiten.
Omdat het forum onderhand stevig gegroeid was, werd ook besloten om het forum een eigen databaseserver te gunnen. Deze server werd naar Apollo vernoemd zodat we qua naamgeving weer teruggingen naar de Griekse mythologie. Apollo werd voorzien van een vrijwel identieke hardwareconfiguratie als Artemis, maar had een iets simpeler moederbord en minder snelle schijven. Wel kreeg hij meer geheugen. Het geheel werd in een 3U Antec-kast geplaatst.
:fill(black)/i/992440848.jpg?f=thumb)
:fill(black)/i/988340535.jpg?f=thumb)
:fill(black)/i/988340536.jpg?f=thumb)
:fill(black)/i/992797696.jpg?f=thumb)
Apollo - de nieuwe GoT-databaseserverAphrodite, die inmiddels met een overleden netwerkkaart thuis bij Kees lag, zou samen met Apollo geplaatst worden. Aphrodite was voorzien van een nieuwe 3Com-netwerkkaart. Beide servers waren deze keer voorzien van een verse Slackware 6-installatie omdat Freebsd slecht was bevallen. Uiteraard buitelden alle Freebsd-fans over ons heen toen wij dit bekendmaakten: Freebsd zou namelijk veruit superieur zijn voor een (database)server. Geen van deze experts kon ons echter helpen om Mysql van meer dan één core gebruik te laten maken.
De uitvoering
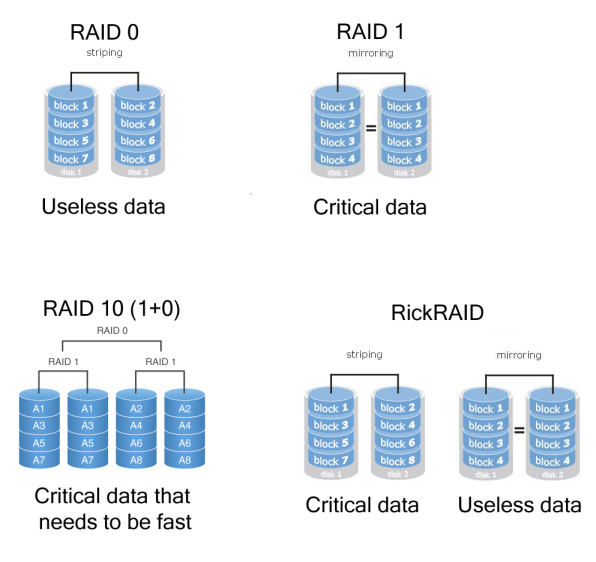
Met Apollo en Aphrodite in de kofferbak reden wij richting Vuurwerk. We hadden op het laatste moment ook nog besloten om de databaseserver Artemis een geheugenupgrade te geven zodat hij in totaal over 2GB geheugen zou beschikken. De geheugenupgrade liep geheel volgens plan, maar nadat de scsi-kabel vervangen was, bleek dat een harde schijf overleden was. Artemis was uitgerust met vier schijven en deze vier schijven hadden in een raid10 moeten zitten. Helaas bleek de definitie van 'raid10' zoals die door de vorige systeembeheerder werd gehanteerd niet geheel overeen te komen met de definitie die de rest van de wereld gebruikt. /i/1221232195.png?f=thumb) Volgens Rick was een raid10 een aparte raid0 en een aparte raid1. Na enig testen was hij er ook uit dat de raid0 beter was voor de database, omdat die meer ruimte had en sneller was dan de raid1. Dit type raid, sindsdien genaamd rickraid, is inderdaad erg snel en je gebruikt inderdaad de volledige grootte van de schijven, maar als er een probleem is met een van de schijven, en die ene schijf is ook nog eens onderdeel van de raid0, dan kun je raden wat er gebeurt...
Volgens Rick was een raid10 een aparte raid0 en een aparte raid1. Na enig testen was hij er ook uit dat de raid0 beter was voor de database, omdat die meer ruimte had en sneller was dan de raid1. Dit type raid, sindsdien genaamd rickraid, is inderdaad erg snel en je gebruikt inderdaad de volledige grootte van de schijven, maar als er een probleem is met een van de schijven, en die ene schijf is ook nog eens onderdeel van de raid0, dan kun je raden wat er gebeurt...
:fill(black)/i/983338831.jpg?f=thumb)
:fill(black)/i/991362686.jpg?f=thumb)
:fill(black)/i/991362687.jpg?f=thumb)
/i/963708090.gif?f=thumb)
Artemis met de dode schijf (tweede van rechts)De nasleep
Na anderhalf uur in de serverruimte gezeten te hebben - ruim een half uur langer dan we er eigenlijk mochten zijn - hebben we Artemis uit het rack getrokken en meegenomen naar een andere locatie om te zien of we nog wat konden redden. Diep in de nacht bleek dat er gewoon niets meer te redden viel en moesten we teruggrijpen op de backup. Het gebruikte backupscript bleek echter ook niet te werken en de laatste backup die we hadden was van 27 april 
Door alle drukte met Artemis en de gelimiteerde tijd die wij bij Vuurwerk mochten doorbrengen, was de installatie van de nieuwe databaseserver nog niet voltooid. In allerijl zijn wij de dag erna weer naar Vuurwerk gegaan om Apollo op te hangen en daar de backup van 27 april op te zetten. Uiteindelijk bedroeg de volledige downtime maar liefst 36 uur, nog steeds met afstand de langste downtime van Tweakers.net ooit.
Met behulp van een groot aantal Tweakers werd begonnen aan een herstelactie van de Frontpage. Dankzij deze herstelactie, en de cache van een aantal gebruikers, zijn er uiteindelijk geen nieuwsposts, reviews en .plans verloren gegaan. Op het forum waren echter wel duizenden posts in een zwart gat verdwenen, maar Onno - die op dat moment bezig was met een zoekmachine voor het forum - had erg veel posts teruggevonden. Desondanks waren veel posts van users door de crash verdwenen. Van de teruggezette posts waren bovendien de tijden verkeerd en was de opmaak verdwenen. Hierdoor duurde het een tijd voordat deze posts teruggeplaatst werden. Uiteindelijk zijn bijna alle forumposts toch weer teruggeplaatst onder de naam van BC3 Victim, die vanaf dat moment met stip de ranglijst van meest postende tweakers aanvoerde.
Verhuizing naar Telecity
Naar Telecity
In de tussentijd werden wij Vuurwerk Internet redelijk zat. Er waren redelijk veel storingen en upgrades aan het netwerk werden laat op de statuspagina vermeld zodat we er soms uren uitlagen voor een upgrade van 'enkele minuten'. Ook mochten wij nauwelijks bij onze servers op bezoek. Het bezoekuur was op woensdagmiddag en dan maximaal een uur, onder het scherpe toezicht van een Vuurwerk-medewerker. Slechts met hoge uitzondering mochten wij langer blijven, en op een andere dag komen was heel erg lastig. Wij waren dan ook zeer geïnteresseerd toen True (in die tijd nog Trueserver) ons benaderde. Trueserver bood ons alles wat Vuurwerk ons ook bood, en meer: ongelimiteerde bandbreedte, een eigen serverrack, het True-netwerk met verschillende uplinks - waaronder maar liefst een gigabit-aansluiting op AMS-IX - en, nog belangrijker, 24/7 toegang tot onze servers.
Over dit aanbod hoefden wij niet heel erg lang na te denken en we planden de verhuizing voor 15 juni 2001. In samenwerking met True werd een mooi plan opgesteld, en een hele boel nieuwe hardware aangeschaft. Bij Vuurwerk werd bijvoorbeeld het interne netwerk geregeld door een 3Com Officeconnect-switch. Deze lag bovenop de servers om het interne netwerk te regelen. Het externe netwerk liep geheel via Cisco-switches van Vuurwerk zelf en voor ons nieuwe rack moesten wij dat zelf gaan verzorgen. Ook wilden wij graag op afstand onze servers kunnen rebooten als ze niet meer reageerden. Op aanraden van True viel onze keuze op een APC Masterswitch, twee managable Micronet 16 poorts 100/10Mbit/s-switches en een non-managable Level One-switch waardoor ons netwerk in principe mooi gescheiden werd en we altijd een backup-switch hadden.
De gereanimeerde databaseserver Artemis en webservers Odin en Aphrodite werden als eerste in het rack op Telecity geplaatst, waarna Artemis zijn taken als databaseserver weer overnam. Vier dagen later werden de laatste servers uit Vuurwerk gered. Zodoende kon Tweakers.net vrijwel zonder downtime overgeplaatst kon worden naar een nieuwe locatie.
:fill(black)/i/992798520.jpg?f=thumb)
:fill(black)/i/992798183.jpg?f=thumb)
:fill(black)/i/992441188.jpg?f=thumb)
:fill(black)/i/992442192.jpg?f=thumb)
:fill(black)/i/992797808.jpg?f=thumb)
:fill(black)/i/992798073.jpg?f=thumb)
:fill(black)/i/992798289.jpg?f=thumb)
:fill(black)/i/992727341.jpg?f=thumb)
Nieuwe switches, nieuwe masterswitch en oude servers in het nieuwe rack Dode netwerkkaarten en harde schijven
Toen de servers eenmaal allemaal bij Telecity stonden bleek dat de netwerkkaarten in een aantal servers niet helemaal gezond meer waren en meer downtime was het gevolg. :fill(black)/i/956473249.jpg?f=thumb) Omdat de vele netwerkproblemen die wij ondervonden voor het grootste gedeelte terug te voeren waren op de gebruikte 3Com-netwerkkaarten - op dat moment een absoluut topmerk - werd besloten om alle 3Com-kaarten overboord te gooien en Intel-kaarten in te zetten. Deze hadden naast betere Linux-ondersteuning ook de neiging minder snel dood te gaan. In totaal zijn er vijf 3Com-netwerkkaarten overleden in de hostingsgeschiedenis van Tweakers.net tegenover slechts één Intel-netwerkkaart.
Omdat de vele netwerkproblemen die wij ondervonden voor het grootste gedeelte terug te voeren waren op de gebruikte 3Com-netwerkkaarten - op dat moment een absoluut topmerk - werd besloten om alle 3Com-kaarten overboord te gooien en Intel-kaarten in te zetten. Deze hadden naast betere Linux-ondersteuning ook de neiging minder snel dood te gaan. In totaal zijn er vijf 3Com-netwerkkaarten overleden in de hostingsgeschiedenis van Tweakers.net tegenover slechts één Intel-netwerkkaart.
In augustus 2001 hadden we weer problemen met harde schijven. Dit keer was Apollo aan de beurt. Via een zeer doordringend alarm gaf deze te kennen dat er iets mis met de server was. Dit was door True opgemerkt en wij werden vriendelijk doch dringend verzocht eens poolshoogte te gaan nemen en het alarm uit te zetten. Eenmaal aangekomen bleek dat één van de twee Quantum Atlas 10k rpm scsi-schijven in Apollo was overleden. Deze tweede overleden schijf in drie maanden tijd zorgde dit keer niet voor dataverlies want de raid1 was deze keer wel goed geconfigureerd. Gelukkig hadden we een Seagate Cheetah X15 bij ons voor Artemis en konden we de overleden schijf meteen vervangen.
Upgrades, upgrades en nog eens upgrades
In de maanden daarop werd veel aan het serverpark gesleuteld. De steeds maar groeiende bezoekersaantallen - van 5 miljoen pageviews in september 2000 tot ruim 25 miljoen pageviews in september 2001 - dwongen ons ertoe om weer nieuwe webservers te plaatsen. De webserver Achelois werd onze eerste webserver met dual processor en draaide op een tweetal AMD Athlon MP 1,2GHz-processors en 1GB geheugen. Omdat de forumsoftware steeds meer van de servers eiste werd besloten om Achelois het forum te laten serveren. Ook werden webservers Odin en Arshia eindelijk voorzien van een Slackware-installatie. De stabiliteit van de Freebsd-installatie was erg slecht en zorgde ervoor dat het forum erg vaak eruit lag. Voor deze herinstallatie draaide het serverpark op een mix van Debian, Slackware en Freebsd en nu waren alle servers Slackware. Ook de namen van de webservers werden veranderd: Odin en Arshia gingen voortaan door het leven als Iris en Arethusa. Apollo onderging enkele upgrades toen bleek dat de 9,1GB schijven bij lange na niet meer voldoende waren om de posts van alle Tweakers op te slaan. De schijfruimte werd verdubbeld door er een tweetal 18,4GB grote schijven in te hangen.
De laatste maanden van 2001 hebben we de colocatie te vaak van binnen gezien. Servers die nog 3Com-kaarten aan boord hadden verloren deze spontaan. Servers werden te warm en werden gekoeld via creatieve oplossingen. De servers kregen nieuw geheugen, gesponsord door Dane Elec. Artemis, die niet met 4GB geheugen overweg kon, kreeg in december, na ruim een jaar trouwe en minder trouwe dienst, een stevige upgrade. De 1GHz PIII's werden vervangen door twee nieuwe AMD 1,4GHz Athlon MP-processors en een nieuw Tyan Thunder-moederbord samen met een nieuwe raidcontroller. Verder werd er een nieuwe fileserver, Atlas, in het rack gehangen. Deze server beschikte over twee 1GHz PIII's, 1GB ram en drie 18,4GB scsi-schijven.
:fill(black)/i/1002639346.jpg?f=thumb)
:fill(black)/i/1006460355.jpg?f=thumb)
:fill(black)/i/1008385187.jpg?f=thumb)
:fill(black)/i/1008385645.jpg?f=thumb)
:fill(black)/i/1006461000.jpg?f=thumb)
:fill(black)/i/1006460097.jpg?f=thumb)
:fill(black)/i/1008385580.jpg?f=thumb)
:fill(black)/i/1008385926.jpg?f=thumb)
Nieuwe servers, server upgrades, modificaties en extra veel koeling zorgt voor een nieuwe Tower of PowerRuim een jaar nadat wij bij Vuurwerk nog twee servers hadden opgehangen, zag ons rack er volledig anders uit. We zaten op een nieuwe locatie en het aantal servers was gegroeid van 2 naar 10 servers, van geen switch hadden we er nu 3 in het rack hangen en we beschikten over een APC Masterswitch. Het grootste gedeelte van dit serverpark hadden we zelf in elkaar geschroefd met veelal gesponsorde onderdelen en dat kwam de stabiliteit lang niet altijd ten goede, dus ondanks alle goede bedoelingen lag de website er toch regelmatig uit of was de site erg langzaam.
Sponsoring en downtimes in 2002
Meer downtimes
In 2002 was het weer raak met een lange downtime. De enige masterswitch in ons rack besloot er spontaan mee op te houden met een nachtelijke reis richting Telecity tot gevolg. Eenmaal daar aangekomen bleek dat de zekering van de Masterswitch gesprongen was, met als gevolg dat acht servers geen stroom meer kregen. Na wat servers uit de masterswitch getrokken te hebben, kon deze weer voldoende stroom leveren en kwamen alle servers zonder problemen een voor een weer up. Na een nacht plat te hebben gelegen konden de meeste Tweakers nog voor hun ontbijt weer op de servers komen.
Sponsoring
In maart 2002 kondigden we verheugd aan dat wij weer een nieuwe sponsor binnengehaald hadden. Procase was bereid gevonden om ons van een nieuw rack te voorzien, inclusief nieuwe cases voor alle servers en een kvm-switch met een ingebouwde lcd-monitor. Dit was natuurlijk heel erg mooi, maar de levering van de producten liet maar op zich wachten. Op het laatst stonden wij zelfs al bij het datacentrum te wachten op de vrachtwagen die ons de goodies zou gaan leveren. Toen deze ruim een uur te laat was, hebben wij het kantoor van Procase nog eens gebeld en werd ons verteld dat de vrachtwagen een lekke band had gekregen onderweg. Na een paar uur wachten en vele telefoontjes verder kwam uiteindelijk het hoge woord eruit: de directie van Procase had besloten de sponsoring in te trekken. Een reden voor het afbreken van de sponsoring en waarom er zoveel excuses werden verzonnen in plaats van het gewoon even te laten weten is ons nooit duidelijk geworden.
Ondanks vele problemen met sponsoring en het niet nakomen van sponsorbeloftes, moesten wij wel doorgaan met deze manier van servers bouwen. Een van de sponsorprojecten die wel goed ging, was het loadbalancer-project. Op 29 mei werden er twee loadbalancers van het merk Brainforce in het rack gehangen. Een van de twee servers werd gesponsord, de andere mochten wij betalen. Omdat wij op dat moment niet heel ruim in het geld zaten, werd de betaalde server weer gewoon geretourneerd naar Brainforce en draaiden we verder met één loadbalancer.
Ook een ander sponsorproject liep in die tijd niet helemaal volgens plan. Van Epox hadden wij een aantal 8KTA3-moederborden gekregen voor gebruik in ons serverpark. Enthousiast als we waren deden we in die tijd niet aan testen, maar werd nieuwe hardware zo uit de doos in productie gegooid. Eenmaal bij de servers aangekomen bleken deze moederborden niet in onze kasten te passen, in plaats van een pci-slot waar een riser ingestoken kon worden, bleek het moederbord op die plek het agp-slot te hebben. Ook een geplande nieuwe databaseserver voor Fok - Alicia - werd lastig omdat het moederbord dat wij meegenomen hadden niet paste in de kast voor die databaseserver. Het moederbord van Apollo paste wel in die kast, dus een snelle on-site swap later hadden wij een werkende databaseserver. Apollo kreeg meteen ook een upgrade van zijn drie 18GB schijven naar vier 36GB scsi-schijven. Doordat de kasten niet helemaal gemaakt waren voor de hoeveelheid hardware die wij erin stopten was het een enorm gevecht om alles weer up en running te krijgen; deze serverupgrade begon rond 11 uur in de ochtend en was pas om 4 uur in de nacht erop klaar.
:fill(black)/i/1022718169.jpg?f=thumb)
:fill(black)/i/1022718297.jpg?f=thumb)
:fill(black)/i/1022718956.jpg?f=thumb)
:fill(black)/i/1022717989.jpg?f=thumb)
Moederbord roulette, nieuwe disks, nauwelijks passende kasten Nieuwe servers, upgrades, opruiming
In de zomer van 2002 stapten wij over naar de forumsoftware van React. Hiervoor moest een aantal servers extra in het rack gehangen worden om de nieuwe forumsoftware te testen. Met deze nieuwe webservers - Ares en Adonis - werd ook de gesponsorde loadbalancer getest. Toen de nieuwe forumsoftware eenmaal online ging werden ook de loadbalancers ingezet zodat downtime tot het verleden moest behoren. Samen met de forumsoftware werden ook de twee nieuwe webservers in de serverpool gezet. Deze twee beschikten over een AMD Athlon XP 2100+-processor, 1GB geheugen en een 10GB Seagate ide-schijf. Dit geheel werd op een Epox 8KHA+-moederbord aangesloten en in een Procase IPC-C2S-kast geplaatst die Procase ons had gestuurd als goedmakertje voor de eerdere mislukte sponsoractie. Met Ares en Adonis in de gelederen bestond het webservercluster uit acht machines, zes voor Tweakers.net en twee voor Fok.
Nog dezelfde zomer werd besloten het rack grondig te verbouwen. Sterker nog, alle servers werden naar een nieuw en dieper rack verplaatst. Door de vele toevoegingen aan het serverpark was dit noodzakelijk geworden. Het was door de kabelbrij in het rack niet meer te zien welke kabel naar welke server liep, en op de gok aan kabels trekken en hopen dat je de juiste had, leek ons geen goed idee. Daarnaast was vrijwel geen enkele server voorzien van sliders, zodat onderhoud aan één server het afbouwen van de halve servertoren betekende. Dit probleem wilden we aanpakken door elke server van een mooie set rails te voorzien. Ook werd de enige niet-zelfbouw server in ons rack eruit getrokken en teruggestuurd naar de fabrikant; al sinds de ingebruikname van die server had hij problemen, met als gevolg dat Tweakers.net er regelmatig een uurtje uitlag. Als laatste werden de Micronet-switches vervangen door 3Coms. De Micronet-switches hadden al voor veel problemen gezorgd, zoals uplinkpoorten die niet meer werkten, een managementinterface waar je alleen op kon komen na een harde reset en poorten die willekeurig uitvielen.
Het plan was om alle servers uit het rack te trekken, een nieuw rack neer te zetten en deze te vullen. In de tussentijd werden ook een heleboel servers geüpgraded. Artemis kreeg twee Athlon MP 2000+ processoren als vervanging van de twee Athlon MP 1600+ processoren en twee extra schijven. Apollo had twee 1GHZ PIII aan boord, en deze werden vervangen door de twee Athlon MP 1600+ processoren uit Artemis en een nieuw moederbord. De databaseserver voor Fok! werd in een nieuwe CI-design kast geplaatst en voorzien van een nieuw moederbord met de 1GHz PIII processoren van Apollo. Ook de webservers kregen upgrades. De 1GHz Thunderbirds werden vervangen door Athlon XP 2000+-modellen met bijpassend Epox-moederbord.
Deze enorme serverupgrade was hard nodig om alle bezoekers een beetje vlot een pagina voor te kunnen schotelen. Ook aan de werkbaarheid van toekomstige serverupgrades werd gedacht. Alle servers hingen nu op sliders en de kabelbrij aan de achterkant was netjes weggewerkt. Een nadeel van op deze manier met hardware schuiven was echter wel dat het erg lang duurde voordat we klaar waren. Ondertussen deden zich allerhande problemen voor: hardware bleek niet te passen, de sliders voor onze database-servers bleken gemaakt te zijn voor een veel minder diep rack en pasten dus niet, een deel van de Epox-moederborden bleek direct vanuit de doos al defecten te hebben en ga zo maar door. Om 19.00 uur vrijdagavond werd begonnen met het onderhoud, en pas de volgende dag rond 13.00 uur waren wij hier mee klaar zodat wij direct naar de grote crewmeeting met barbecue konden doorrijden. Halverwege het onderhoud verloren wij ook nog de database van Fok, zodat we voor hen een backup van de dag ervoor moesten terugzetten.
:fill(black)/i/1030992355.jpg?f=thumb)
:fill(black)/i/1031004577.jpg?f=thumb)
:fill(black)/i/1031005123.jpg?f=thumb)
:fill(black)/i/1031005207.jpg?f=thumb)
:fill(black)/i/1031005412.jpg?f=thumb)
:fill(black)/i/1031006214.jpg?f=thumb)
:fill(black)/i/1031007102.jpg?f=thumb)
:fill(black)/i/1031007155.jpg?f=thumb)
Megaserverupgrade en opruiming Dual Xeon Appro's
Ondanks de slechte ervaringen met niet-zelfbouw servers, hadden wij het vertrouwen in dit type servers niet helemaal verloren. Dus toen Teranet ons twee prefab Appro-servers wilde sponsoren twijfelden wij niet lang. De eerste 1U Appro-bakken werden in november 2002 in het rack gehangen en werden Acidalia en Abaris gedoopt. Later werden er nog twee Appro-servers aangeschaft om een aantal webservers te vervangen. Ares, Abaris, Acidalia en Adonis de 4 Appro-servers beschikten over twee 2,4GHz Xeons, 1GB geheugen en een 20GB grote schijf. Deze servers zijn zo betrouwbaar gebleken dat op het moment van publicatie drie van de vier Appro-servers - ruim 6 jaar na hun ingebruikname - nog steeds trouw dienst doen op het kantoor en in het rack als testservers. Alleen Acidalia overleed na enige tijd met een kapotte voeding, waarmee deze server het halve rack wist plat te leggen.
Upgrades en uitbreidingen
Fileserver blues
Eind 2002 en begin 2003 ging het er redelijk rustig aan toe. Met de megaserverupgrade achter de rug werd het serverpark eindelijk stabieler en voor de verandering ging niet alles in deze periode fout. De databaseservers Artemis en Alicia doorbraken op woensdag 14 mei 2003 de 250 dagen uptime, een enorme prestatie in die tijd voor ons. Met alle server verbouwingen en crashende Mysql-servers waren we normaal al blij als de servers het een maand uithielden. Overigens is op het moment van schrijven de gemiddelde uptime van alle servers bij elkaar bijna 300 dagen.
Na onze slechte ervaringen met de eerste fileserver, en haast nog slechtere ervaringen met een tweede fileserver, besloten wij deze keer het goed aan te pakken. Een Compaq ML530, Dual Xeon 2,8GHz met 4GB geheugen en in totaal bijna 800GB aan schijven zou onze volgende fileserver worden. Dit geheel was in een gigantische 7U kast geplaatst en op 17 juni 2003 in ons rack gehangen. Deze server zou niet alleen de files gaan serveren, maar ook backups maken en de forumsearch uitvoeren. Voor de backups werden er drie 200GB Maxtor-schijven in raid5 gedrukt, terwijl voor het serveren van de files in eerste instantie vijf 36GB Seagate scsi-schijven werden gebruikt. Later werden hier nog schijven bijgeplaatst zodat het totaal op tien 36GB SCSI schijven kwam. Hoewel alles goed leek te gaan, gingen er in Atlas achter elkaar enkele schijven kapot. Eenmaal op locatie aangekomen bleek het om dezelfde bay te gaan. De disk werd uiteraard in een andere bay geprobeerd, maar het was al te laat; de infameuze tweede bay had zijn derde slachtoffer in een paar weken tijd gemaakt. Hierna werd de desbetreffende bay permanent tot verboden gebied verklaard, waarna alle schijven in goede gezondheid bleven.
Niet alleen de scsi-schijven in Atlas hadden korte levens. Ook de 200GB Maxtor ide-schijven, die in een Full-5,25”-hotswapbay zaten, werden warm. Ruim 100 graden noteerde een sensor in de middelste schijf op een moment. Nadat ook deze schijf overleden was, besloten we het geheel maar op een tweetal schijven in een raid1 te zetten in plaats van drie schijven in raid5.
:fill(white)/i/1221494805.jpg?f=thumb)
:fill(white)/i/1221494825.jpg?f=thumb)
:fill(white)/i/1221494851.jpg?f=thumb)
:fill(white)/i/1221494867.jpg?f=thumb)
Ruim 60kg schoon aan de haak: Compaq ML530 Atlas Databaseserver upgrades
Databaseserver Artemis was ondertussen weer hoognodig aan vervanging toe. We besloten een gok te nemen en de net gereleasde AMD Opteron-processors uit te proberen in ons rack als vervanging van de inmiddels bejaarde Athlon MP-processors waar Artemis nog steeds trouw dienst mee deed. Omdat we onderhand goede ervaringen met Appro hadden, besloten we om opnieuw met deze barebones aan de slag te gaan.
Met een recorduptime van 422 dagen ging Artemis II op 3 november 2003 eindelijk uit en werd hij opgevolgd door Artemis III, een Dual AMD Opteron 246 met 4GB geheugen en 4x Seagate Cheetah 10K.6 36.7GB SCSI schijven in een Appro 2128Hs barebone. Artemis III stond al de hele zomer bij ons op het kantoor, maar doordat de processors, AMD Opteron 242, onmogelijk wilden samenwerken met 6GB geheugen en het installeren van een 64bits bèta-OS niet altijd even vlekkeloos verliep, duurde het een tijd voordat deze server stabiel genoeg werd bevonden. Ook draaide er op deze server geen Slackware maar een bèta van Suse 8 omdat dit de eerste x86_64-processors waren en er gewoon geen 64bits Slackware voor handen was. Ook Apollo, die een korte tijd later naar eenzelfde model barebone werd geüpgraded, (maar met 2GB meer geheugen) draaide in eerste instantie op een bèta van Suse 8. Na de upgrade bleek dat de frontpage bizar snel werkte. De meeste pagina's werden twee keer zo snel op de servers opgebouwd als voorheen.

:fill(black)/i/1067639757.jpg?f=thumb)
:fill(black)/i/1068150800.jpg?f=thumb)
:fill(black)/i/1071938904.jpg?f=thumb)
:fill(black)/i/1068149961.jpg?f=thumb)
Appro barebones in het rack en het effect ervan op de cpubelasting
Verhuizing naar Redbus
Nieuwe switches en consoleserver
Ook in 2004 werkten we weer druk aan het serverpark. Zo werd in februari het interne netwerk voorzien van een gigabit-switch, werd Achelois vervangen door een pre-made server en werd er een Cyclades Consoleserver opgehangen. Deze Cyclades was voornamelijk bedoeld om servers op afstand te kunnen beheren. De meeste biossen in onze servers konden de console doorsluizen naar een seriële poort, en deze werd vervolgens op de Cyclades aangesloten.
:fill(black)/i/1076430679.jpg?f=thumblarge "Cyclades Alterpatch ACS console switch detail")
:fill(black)/i/1076430680.jpg?f=thumblarge "3Com SuperStack 3 3824 en Cyclades Alterpatch ACS console switch DOF")
Toch was dit niet ideaal: het werkte niet altijd. Om ook de bootlog op het scherm te toveren moesten er bovendien een aantal extra commando's worden gegeven in de bootprompt. Helaas was de seriële verbinding soms zo langzaam dat de bootprompt -die 5 seconden blijft staan- alweer verdwenen was voor het invoeren, waarna we de server weer moesten rebooten voor een nieuwe poging, in de hoop dat wij het euvel konden vinden. Toch was het apparaat in veel gevallen een uitkomst.
Fok! naar Redbus
De samenwerking met Fok! op servergebied liep in 2004 ook ten einde. Al sinds het ontstaan van Fok! werd deze site door Tweakers.net gehost, maar na ruim 5 jaar gebroederlijk samen te hebben gewerkt was het tijd voor Fok! om een eigen rack te krijgen bij Redbus. Deze splitsing werd mede ingegeven door het feit dat ons rack op Telecity ondertussen tot de nok toe gevuld was. Omdat ook Tweakers.net nog steeds redelijk hard groeide, en onze databaseservers niet altijd even vrolijk meededen, gingen wij weer op zoek naar een nieuwe server.
Toen deze eenmaal geleverd was, hadden we problemen met de risers, de voedingen waren niet sterk genoeg en al met al duurde het lang voordat de server stabiel was. In eerste instantie wilden we een 2U Appro nemen, die was ons uitermate goed bevallen maar het bleek dat deze behuizing te klein was, gelet op onze hardware-eisen. Uiteindelijk werd er gekozen voor een 3U Chenbro-behuizing, en omdat we ook de backups eindelijk goed wilden regelen werd er een tweede 3U Chenbro gevuld. Toen we deze in het rack hingen ging er oude droom in vervulling: een kvm-switch met lcd in een lade.
:fill(white)/i/1222707810.jpg?f=thumb)
:fill(white)/i/1222707832.jpg?f=thumb)
:fill(white)/i/1222707873.jpg?f=thumb)
:fill(white)/i/1222707900.jpg?f=thumb)
Fok! serververhuizing - volle en lege racks Tweakers.net naar Redbus
Onze hostingprovider, True, was bezig om zoveel mogelijk klanten van Telecity naar Redbus te krijgen, en op 26 oktober 2004 moesten ook wij eraan geloven. Onze voordelen waren talrijk: Redbus had een betere stroomvoorziening, een betere airco en ons rack zou maar liefst 100 centimeter diep worden. Ons hele hebben en houden dat bij Telecity stond werd verplaatst naar Redbus. Slechts een enkele server bleef achter om onze bezoekers te voorzien van wat informatie betreffende de verhuizing. Rond 7 uur in de ochtend vertrokken wij richting Telecity om daar alle servers uit te zetten en los te schroeven, waarna we ze met auto's richting Redbus konden vervoeren. Daar werden alle servers weer een voor een in een nieuw en dieper rack gehangen en rond vijf uur in de middag was alles weer online. Al met al een verhuizing die veel tijd koste, maar waarbij gelukkig weinig mis ging. Alleen de mailserver wilde niet meer booten, maar een snelle hardwaretransplantatie met een webserver als donor verder deed deze ook weer gewoon mee.
:fill(black)/i/1099350451.jpg?f=thumb)
:fill(black)/i/1099344429.jpg?f=thumb)
:fill(black)/i/1099343580.jpg?f=thumb)
:fill(black)/i/1099334043.jpg?f=thumb)
:fill(black)/i/1099344992.jpg?f=thumb)
:fill(black)/i/1099348863.jpg?f=thumb)
:fill(black)/i/1099348961.jpg?f=thumb)
:fill(black)/i/1099350932.jpg?f=thumb)
Kleine impressie van de serververhuizing. Meer foto's en de offline pagina die werd weergegeven tijdens de verhuizing kun je hier vinden

































































:strip_icc():strip_exif()/i/2001246513.jpeg?f=fpa_thumb)

:strip_icc():strip_exif()/u/3496/ford_power_klein.jpg?f=community)
/u/8/oog3.png?f=community)
:strip_exif()/u/22713/liekevlecht2.gif?f=community)
:strip_icc():strip_exif()/u/46056/rascal_small.jpg?f=community)
:strip_exif()/u/34956/crop5f18a17d7693c.gif?f=community)
:strip_icc():strip_exif()/u/174221/crop622fcedcbc717_cropped.jpg?f=community)
/u/14460/despicable_me.png?f=community)
:strip_exif()/u/27690/Misc_-_Boy.gif?f=community)
:strip_icc():strip_exif()/u/3550/S2462.jpg?f=community)
/u/127226/Gunsicon.JPG?f=community)
/u/46804/crop5f989efcbb253.png?f=community)
:strip_exif()/u/56159/archer.gif?f=community)
:strip_icc():strip_exif()/u/43473/crop5e12eeae6a054_cropped.jpeg?f=community)
:strip_exif()/u/23576/garfield.gif?f=community)
:strip_icc():strip_exif()/u/264054/johnnie_walker60.jpg?f=community)
/u/27131/crop61572b353fff1_cropped.png?f=community)