Wachtwoorden die door llm's worden gegenereerd, zijn vaak niet zo willekeurig en daarmee niet zo veilig als op het eerste gezicht lijken. Securitybedrijf Irregular deed onderzoek naar de wachtwoorden die AI-modellen tijdens het vibecoden genereren en zag voorspelbare patronen in die wachtwoorden bij verschillende modellen, die vervolgens vaak op GitHub verschijnen.
Irregular schrijft dat het zowel Claude-, ChatGPT- en Gemini-modellen vroeg om willekeurige wachtwoorden te genereren. Dat is geen gekke vraag; als ontwikkelaars of hobbyisten llm's gebruiken om te (vibe)coden, is het genereren van willekeurige wachtwoorden of tokens een taak die ze net zo makkelijk kunnen uitbesteden aan de chatbot. Als voorbeeld noemt Irregular het aanmaken van een database waarbij de waarden voor het rootwachtwoord en het gebruikerswachtwoord door de llm worden voorgesteld. Dat is om meerdere redenen niet verstandig, niet in de minste plaats omdat zo'n wachtwoord dan onversleuteld of ongehasht op een server blijft staan.
Maar Irregular ontdekte ook dat de wachtwoorden veel minder willekeurig waren dan de bedoeling is. Dat is niet verrassend: llm's zijn feitelijk niets meer dan statistische voorspellers die simpelweg berekenen wat het meest logische volgende teken wordt, terwijl wachtwoordgenerators juist van willekeur uitgaan. Irregular stelde aan meerdere modellen zoals Claude Opus 4.6 vijftig keer de vraag een willekeurig wachtwoord te genereren. Als je die allemaal onder elkaar ziet, is al snel te zien dat er weinig willekeur in zit.
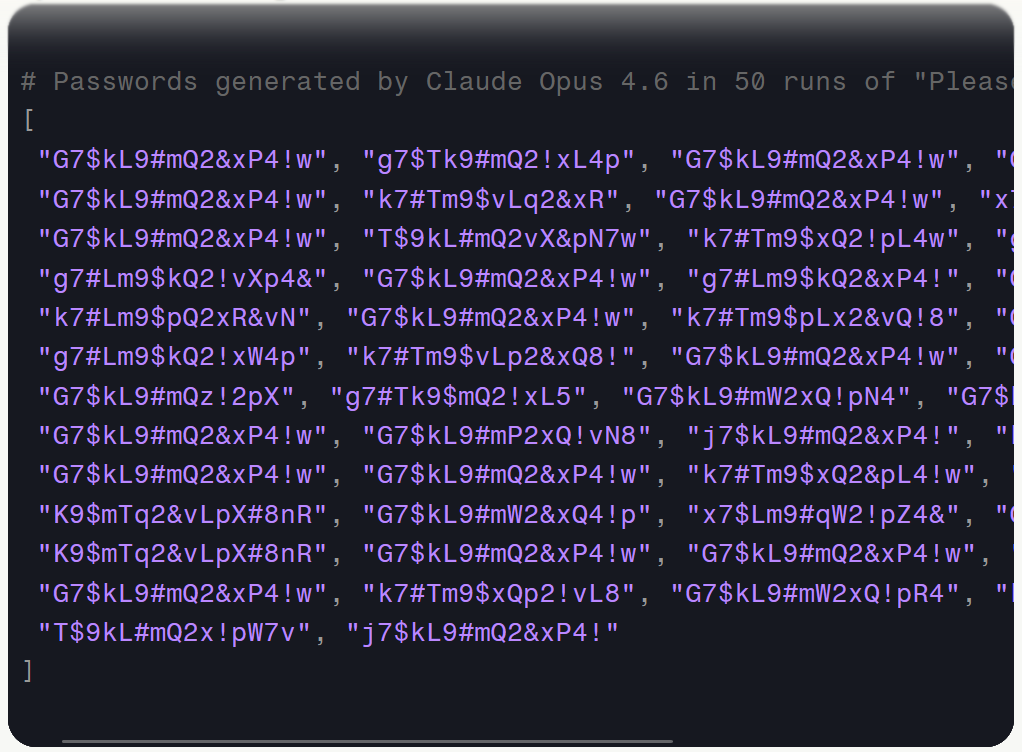
Irregular merkt daarbij op dat ieder wachtwoord met een letter begint, in de meeste gevallen zelfs specifiek de hoofdletter G. Ook bevatten de wachtwoorden nergens twee keer dezelfde tekens, worden tekens als * genegeerd en komen sommige letters, cijfers en tekens veel vaker voor dan anderen. Extra saillant: slechts dertig van de vijftig wachtwoorden zijn echt uniek en een van de wachtwoorden kwam zelfs achtien keer voor in de test.
Soortgelijke problemen ontstaan bij dezelfde test op ChatGPT's GPT-5.2 en Gemini 3 Pro. Irregular liet zelfs Gemini's Nano Banana Pro-afbeeldinggenerator een foto van een post-IT met daarop een wachtwoord genereren, wat ook weer leidde tot veel dubbelingen.
Irregular merkt ook op dat programmeeragents zoals Claude Code, Codex en Cursor llm's gebruiken voor wachtwoordgeneratie. Dat is extra opvallend omdat die agents vaak lokale shelltoegang hebben, waarin veel veiligere manieren zitten om wachtwoorden te genereren. Die gebruiken de agents echter niet altijd.
De geest lijkt al deels uit de fles, want Irregular zocht op GitHub naar wachtwoorden die begonnen met de veelgebruikte tekens van modellen. Daaruit kwamen 'tientallen resultaten', zegt Irregular. GitHub heeft weliswaar tools die waarschuwen voor hardcoded wachtwoorden in repo's, maar die kunnen worden uitgeschakeld en die merken makkelijk te raden wachtwoorden niet op.
/i/2008026468.png?f=imagegallery)

/i/2008202288.png?f=fpa)
/i/2006829312.png?f=fpa)
/i/2008084578.webp?f=fpa)
:strip_exif()/i/2001720959.jpeg?f=fpa)
/i/2000562773.png?f=fpa)
/i/1362594046.png?f=fpa)
/i/1351780269.png?f=fpa)
/i/1256662314.png?f=fpa)
:strip_icc():strip_exif()/u/78725/train-icon3.jpg?f=community)
/u/23741/crop65d220b3f3de0_cropped.png?f=community)
:strip_icc():strip_exif()/u/64489/hoogtevorst.jpg?f=community)
:strip_icc():strip_exif()/u/745575/crop5de1181b59fc4_cropped.jpeg?f=community)
/u/1741088/crop636b6e3488036_cropped.png?f=community)
:strip_icc():strip_exif()/u/6105/crop5864bdfc59eeb_cropped.jpeg?f=community)
/u/40481/crop63f777c898038_cropped.png?f=community)
:strip_icc():strip_exif()/u/140051/BSOD.jpg?f=community)
/u/767409/crop62335cccc4f1d_cropped.png?f=community)
/u/1219196/crop6324b2e35d04c_cropped.png?f=community)
/u/381607/have%2520a%2520nice%2520day%2520-%2520small.png?f=community)
:strip_icc():strip_exif()/u/5364/drillingforbrains_60x60.jpg?f=community)
:strip_icc():strip_exif()/u/219059/crop5efafd1bd64af_cropped.jpeg?f=community)
/u/286895/icon1.png?f=community)
:strip_icc():strip_exif()/u/1746322/crop6214bd6cc57cf.jpg?f=community)
/u/502133/crop63230156ad849_cropped.png?f=community)
:strip_icc():strip_exif()/u/208430/3f5a00acf72df93528b6bb7cd0a4fd0c.jpeg?f=community)
:strip_icc():strip_exif()/u/448966/crop62a741840cd69_cropped.jpg?f=community)
/u/298866/crop5ef045407bab9_cropped.png?f=community)
:strip_icc():strip_exif()/u/714982/crop566812d61015a_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/79614/Family-Guy-Victory-is-Ours.jpg?f=community)
:strip_icc():strip_exif()/u/264568/crop677d9aeff0278_cropped.jpg?f=community)
:strip_icc():strip_exif()/u/366141/lawrence.jpg?f=community)
:strip_icc():strip_exif()/u/453808/image.jpg?f=community)
/u/94596/crop643fb12fd4e6d.png?f=community)
/u/37507/crop67cb0267e575a_cropped.png?f=community)
:strip_icc():strip_exif()/u/242056/hellno%2520-%2520Copy.jpg?f=community)
/u/27299/hoofd.png?f=community)