Lumex zonder Cortex en Immortalis
Tijdens zijn jaarlijkse Tech Client Days heeft het Britse Arm zijn nieuwste platform voor de consumentenmarkt onthuld. Het zal niemand verbazen dat alles doorspekt is met AI, maar dat is niet de enige focus van de chipontwerper. Het nieuwe Lumex-platform heeft een nieuwe generatie cpu-cores, een nieuwe gpu en een nieuwe interconnect, en bovendien kun je voortaan kiezen tussen niet drie, maar vier cpu-cores. Daarbij is de naam Cortex verleden tijd en ook Immortalis komt niet meer terug in de gpu.
Het nieuwe Lumex-platform is de codenaam die Arm hanteert voor de opvolger van CSS for Clients, dat in 2024 werd geïntroduceerd en dat op zijn beurt de opvolger was van Total Compute Solutions (TCS). Lumex bouwt voort op de cpu- en gpu-cores, de overige hardware en natuurlijk de software van vorig jaar, maar dan met vernieuwde hardware en een splinternieuwe core. De dagen van het oude big.Little-concept waren met de komst van de X-cores een paar jaar geleden al geteld, maar dat idee gaat nu nog verder op de schop.
Bovendien is het gedaan met Immortalis, de naam voor de krachtigste gpu's die Arm te bieden had. Krachtige gpu's zijn er nog steeds, maar die vallen voortaan, net als alle andere configuraties, gewoon onder de Mali-vlag. En dan is er nog nieuws op AI-acceleratorvlak, want hoewel Arm nog altijd geen echte neural processing unit (npu) maakt, heeft de ontwerper nu een bijna-core die daar erg dicht in de buurt komt.
Om al deze ontwikkelingen op een rijtje te zetten, gaan we de afzonderlijke onderdelen langs. We starten met de cpu-cores, om via de gpu-cores bij het platform en de bijbehorende ontwikkeltools uit te komen. De bijna-core kan zowel onder de cpu-cores als onder het platform − en dan met name de ontwikkeltools ervoor − geschaard worden, maar voor de overzichtelijkheid en correcte taxonomie vind je die SME2-unit bij de cpu-cores terug.
:strip_exif()/i/2007721558.jpeg?f=imagenormal)
Cpu-cores: Nano, Pro, Premium en Ultra
Even een herinnering: de cores van vorig jaar bestonden uit drie formaten. De grootste en krachtigste was de Cortex-X925, de opvolger van de Cortex-X4. Daarmee brak Arm met de eerdere naamconventie, want Cortex-X1 tot en met Cortex-X4 volgden elkaar op. De nieuwe topcore draagt de Cortex-naam niet meer en heet voortaan de C1-Ultra. Ook in de rest van de Lumex-cores verdwijnt de naam Cortex. We bekijken straks de verbeteringen in de C1-Ultra en de overige cores, maar eerst gaan we in op de overige cores.
:strip_exif()/i/2007721398.jpeg?f=imagenormal)
De kleinste core heet voortaan Nano, in dit geval de C1-Nano. Die volgt de Cortex-A520 van vorig jaar op. De voormalige grote core, de Cortex-A725, heet voortaan de C1-Pro. De nieuwe core, die tussen de Ultra en Pro wordt gepositioneerd, is de C1-Premium. Die is te beschouwen als een afgeslankte Ultra-core. Daarmee is het aanbod verder gespreid en kunnen alle cores, zoals gebruikelijk, door de klanten van Arm worden afgestemd. Zo is bijvoorbeeld de hoeveelheid cache variabel en kunnen spanningen en klokfrequenties worden afgestemd voor een mix van optimale prestaties en maximale energie-efficiëntie.
Kloksnelheden en caches
Over klokfrequenties gesproken: het cpu-cluster van Lumex is nog steeds geoptimaliseerd voor productie op 3nm-nodes. Dat neemt niet weg dat er verbeteringen in snelheid mogelijk zijn: een dieshrink is dus niet noodzakelijk om hogere klokfrequenties te halen. Ter illustratie ligt de klokfrequentie van de snelste cores, de C1-Ultra, aanzienlijk hoger dan de maximale snelheid van de Cortex-X925 van vorig jaar. Die liep op maximaal 3,6GHz (al noemt Arm ook 3,8GHz als maximum), waar de C1-Ultra voor 4,1GHz gespecificeerd wordt. Dat is uiteraard wel afhankelijk van afdoende koeling en in de praktijk worden die pieksnelheden zeer zelden of nooit geïmplementeerd. In de validatieopstelling, op een field-programmable gate array (fpga) als platform, laat Arm de Pro-cores op 3,5GHz draaien en de SME2-unit iets langzamer op 2GHz. Snelheden voor de Premium- en Nano-cores heeft Arm overigens niet vermeld.
:strip_exif()/i/2007721404.jpeg?f=imagenormal)
De caches van de nieuwe cores − tenminste voor validatie in het fpga-platform − zijn over het algemeen vergelijkbaar met het CSS-platform van vorig jaar. De C1-Ultra krijgt 2MB L2-cache, maar wel een dubbel zo grote L1-datacache ten opzichte van de X925: 128kB versus 64kB. De L1-instructiecaches zijn even groot, met 64kB. Voor de Pro-cores heeft Arm 1MB L2-cache aangehouden en de L1-data- en instructiecaches zijn beide 64kB, net zo groot als bij de A725. De instruction translation lookaside buffer (itlb) is wel groter, met 48 versus 32 entry's. Van de Nano-cores (en de Premium-cores) geeft Arm geen details. Wel is het aannemelijk dat de Nano-cores, net als de A520-cores van vorig jaar, weer 512kB gedeelde L2-cache hebben per twee cores en 64kB L1-instructie- en datacaches hebben, aangezien Arm geen aanpassingen heeft genoemd.
SME2: een bijna-npu
En dan is er nog de beloofde bijna-core, het AI-werkpaard dat volgens Arm een flinke sprong in AI-berekeningen gaat maken. Een echte core is het niet, want het is onderdeel van het cpu-cluster, maar de SME2-unit is wel min of meer gescheiden van de overige cores. SME2 staat voor Scalable Matrix Extensions 2 en vormt onderdeel van de Armv9.2-architectuur. Zoals de naam aangeeft, is het bedoeld voor matrixberekeningen en die worden in AI-toepassingen veel gebruikt. Toepassingen als stemherkenning met Whisper, Stable Audio-geluidsproductie en Gemma 3 voor llm’s profiteren flink van SME2. Volgens Arm zou de gemiddelde verbetering over courante AI-workloads 3,7 keer zijn. Daarmee zouden veel meer AI-toepassingen lokaal in plaats van in de cloud kunnen draaien, wat latency (en privacy) ten goede komt.
:strip_exif()/i/2007721410.jpeg?f=imagenormal)
De redenering van Arm om de SME2-unit toe te voegen, zou je kunnen samenvatten in één zinnetje: developers zijn lui. Helemaal serieus is dat niet en ik wil Arm die woorden ook niet in de mond leggen. Maar de langere uitleg is: een Arm-core is altijd beschikbaar voor developers en daardoor vaak het eerste 'target' voor het schrijven en uitvoeren van code. Ook als het om een AI-toepassing gaat, is er altijd een Arm-cpu in de soc aanwezig waarop je code gewoon draait. Als je naar een gpu of − indien beschikbaar − een npu moet uitwijken, zul je enerzijds veel builds moeten maken omdat gpu's en npu's variëren in verschillende socs. Anderzijds voeg je complexiteit toe, omdat sommige stukjes code eerst op de cpu draaien, waarna data naar een gpu of npu wordt gestuurd, om vervolgens weer door de cpu opgepakt te worden. Door npu-achtige features in de cpu beschikbaar te maken via SME2, zou AI-code op veel hardware sneller draaien, zonder dat een npu nodig is. Natuurlijk, benadrukt Arm, staat het hun klanten nog altijd vrij om hun eigen npu's in de soc te implementeren en zich zo te onderscheiden van andere aanbieders.
De reden om de SME2-unit niet als core te bestempelen, is dat het niet echt een core is. Fysiek is hij wel gescheiden van de overige cores, maar hij is direct onderdeel van die cores, net als een arithmetic logic unit (alu) of load-store unit (lsu). En hoewel hij via het DSU-fabric (de DSU zijn onder meer de core-interconnects en de caches: meer over de nieuwe DSU lees je hier) met de rest van de cores verbonden is, wordt geen bandbreedte van de DSU gebruikt. Ingewikkeld? Ja, zeker als je bedenkt dat de SME2-unit niet in elke core zit, maar als apart logicblok toegevoegd kan worden. Vooralsnog is het logisch slechts één SME2-unit aan een corecomplex toe te voegen, omdat er over het algemeen niet meerdere AI-workloads parallel hoeven te draaien en diespace al duur genoeg is. Het is wel mogelijk meerdere (twee) SME2-units in een soc te plaatsen, of een klant kan kiezen er helemaal geen in te bouwen. Arm adviseert dat echter alleen bij de kleinste configuraties achterwege te laten, zoals bij wearablesocs met twee Nano-cores.
:strip_exif()/i/2007721406.jpeg?f=imagenormal)
Het is overigens niet voor het eerst dat Scalable Matrix Extensions in Arm-cores te vinden zijn. Zo heeft Apple een SME-implementatie in zijn M4-chips, al is SME meer geschikt voor hpc dan voor mobiele toepassingen. Ook Arm heeft voor zijn zakelijke hpc-modellen SME toegevoegd, maar deed dat niet in de vorige generatie voor consumenten. SME2 zou zich veel beter voor workloads lenen waarmee eindgebruikers te maken krijgen.
Architectuur achter C1-cores
Elk jaar voert het Arm-team verbeteringen aan de cores, gpu-shaders, fabric en overige componenten door. De verbeteringen in de cores, de frontend en backend lopen we voor de verschillende C1-cpu's één voor één door. Fundamenteel zijn die nauwelijks veranderd, maar er zijn ook dit jaar weer bottlenecks weggenomen. De C1-cores zijn voorzien van de Armv9.3-architectuur, met hier en daar een toefje van Armv9.4.
C1-Ultra
De Ultra-core, de opvolger van de X925-core, heeft nog steeds een 10-wide execution window, maar dat wordt beter benut, wat resulteert in een prestatieverbetering van − volgens Arm − maar liefst 25 procent. Let wel: dat is vergeleken met een X925-core op 3,6GHz en een C1-Ultra op 4,1GHz, een verschil van 14 procent. Bovendien gebruikt Arm Geekbench 6.3 voor de singlethreaded prestatiecijfers en een subscore daarvan profiteert van de SME2-ondersteuning in de C1-Ultra, al zou de invloed daarvan beperkt zijn. Netto, in instructions per cycle (ipc) uitgedrukt, claimt Arm nog steeds een ipc-winst van dubbele cijfers, maar dat zal dan nipt in de tienprocentrange zijn.
Die winst heeft Arm voornamelijk gerealiseerd door verbeteringen in de branch prediction en een hogere bandbreedte van de instructiecache in de frontend. In de backend is de L1-datacache verdubbeld tot 128kB en is het out-of-orderwindow met 25 procent vergroot. Zo kunnen meer instructies bij elkaar gezocht worden die parallel uitgevoerd kunnen worden. Afhankelijk van welke metric je volgt, kunnen er ongeveer 2000 instructies 'in flight' zijn. Dat alles moet ervoor zorgen dat de core zo optimaal mogelijk benut wordt en niet hoeft te wachten op instructies.
Dat alles levert vergeleken met de X925 een prestatiewinst van die genoemde 25 procent op, mits koeling en implementatie van de productie in orde zijn. En als de prestaties van de C1-Ultra gelijk gehouden worden aan die van de X925, heeft deze daar 28 procent minder energie voor nodig. Dat laatste is vooral handig voor langdurige, intensieve taken zoals gaming, terwijl de piekprestaties vooral belangrijk zijn voor het starten van applicaties en andere korte intensieve taken.
C1-Premium
De Premium-cores zijn helemaal nieuw en worden door Arm tussen de Ultra- en Pro-cores gepositioneerd. Om het in oudere termen te zeggen: ze zitten dus tussen de X925 en A725 in. De Premium-cores zijn bedoeld voor (met name) telefoons waarbij goede prestaties belangrijk zijn, maar er ook op de kosten gelet moet worden. Vergeleken met de Ultra-cores zijn de Premium-cores namelijk zo'n 35 procent kleiner en dat levert, met de steeds hogere waferproductiekosten, een flinke besparing op. Bovendien hoeven fabrikanten niet direct terug te vallen op alleen de Pro-cores (de opvolger van de A725 dus) met hun lagere prestaties. Vergeleken met die Pro-cores zijn de Premium-cores namelijk nog altijd 35 procent sneller, maar wel langzamer dan de Ultra-cores.
:strip_exif()/i/2007721426.jpeg?f=imagenormal)
Om dat te bewerkstelligen, zijn de Premium-cores afgeslankte Ultra-cores, met wat minder L2-cache, kleinere vectorunits en wat Arm simpelweg de 'fysieke implementatie' noemt. Daar komen we straks nog op terug, want Arm heeft ook voor het Lumex-platform weer ontwerpen die kant-en-klaar voor tape-out zijn.
C1-Pro
Het traditionele werkpaard van het cpu-cluster is de grote core: de C1-Pro dus, als opvolger van de Cortex-A725. Vergeleken met die A725 is de nieuwe Pro-core bij gelijke klokfrequentie (en overige configuratie) zo'n 10 tot 16 procent sneller dan de A725 en bij gelijke prestaties circa 12 procent zuiniger. Overigens meldt Arm in een andere slide een winst van 11 procent bij isovermogen en 26 procent energiebesparing bij isoprestaties; die cijfers zijn afkomstig van gesimuleerde cores en bereikt met Geekbench 6.3.
De Pro heeft een dubbele functie, afhankelijk van de andere cores waarmee hij gecombineerd wordt. In combinatie met de Ultra- of Premium-cores doet hij het werk van de oude Little-cores: achtergrondtaken en lange werklasten die minder veeleisend zijn en niet op de grootste cores hoeven draaien. In andere configuraties met Nano-cores heeft hij zijn traditionele rol van big-core.
De verbeteringen heeft het Pro-team bereikt door de core efficiënter te maken. Zoals vrijwel elk jaar is flink gesleuteld aan de branch prediction, aangezien dat een dankbaar doelwit is met veel winstpotentieel. De branch predictor is groter geworden en ook de geschiedenis van branch predictions is uitgebreid. Zo is de frontend beter in staat langere en complexere code te voorspellen. Voor de situaties waarin code te groot is om in de buffers te passen, is ook de statische voorspelling uitgebreid. De verbeteringen zorgen ervoor dat de core minder onzinnige (foutvoorspelde) code uitvoert en zo werk en klokcycli verspilt. Ook de 0- en 1-cyclebuffers voor de branch predictor (waar de volgende voorspelde instructies opgeslagen worden) zijn uitgebreid met een verdubbeling en verzestienvoudiging, waardoor de pipeline nooit hoeft te haperen. Dat draagt ook flink bij aan energiebesparingen.
In de backend heeft de datacache meer bandbreedte gekregen zonder meer ruimte in te nemen of extra energie te vergen. Om nog meer energiebesparingen te realiseren, is de prefetcher verbeterd, zodat er minder vaak naar gedeelde caches in het DSU of zelfs helemaal naar het ram uitgeweken hoeft te worden. Dat levert ook prestatiewinst op, maar vooral naar ram gaan voor data kost veel energie. Daarmee heeft de Pro-core flinke verbeteringen in snelheid en energiebeheer gekregen om zijn dubbele rol te kunnen vervullen.
Overigens ontwerpt Arm ook zogenoemde 'area-optimized'-versies van zijn (voorheen) big-cores. Daarbij heeft het versies van de C1-Pro die ongeveer even groot zijn als de A78-core uit 2020 en de A720 uit 2024, maar die een flinke prestatiewinst leveren. Dat moet migratie van oudere ontwerpen naar het nieuwste platform eenvoudiger maken, en biedt betere prestaties zonder veel extra waferkosten.
C1-Nano
De C1-Nano, ten slotte, is voor de energiezuinige configuraties bedoeld. Ze zijn veel efficiënter geworden dan de vorige superzuinige cores: Arm noemt 26 procent verschil, puur op basis van de architectuur, dus niet op geoptimaliseerde procedés. Daarnaast zijn ze ook iets sneller geworden, al is dat verschil ongeveer 5 procent. Wel zijn ze marginaal groter geworden − een verschil van 2 procent − maar dat wordt ruimschoots gecompenseerd door de hogere prestaties.
Nieuwe C1-DSU
De DynamIQ Shared Unit (DSU) is de lijm die de cpu-cores bij elkaar houdt. Die zorgt voor de communicatie tussen de cores en huisvest ook de L3-caches en de interfaces met andere onderdelen van de soc. Nieuw in de C1-DSU is ondersteuning voor de SME2-units: daarvan kunnen er in principe twee worden ondersteund, maar in de praktijk raadt Arm aan er maar één te plaatsen. Het maximale aantal cpu-cores is onveranderd gebleven ten opzichte van de vorige versie: er passen maximaal 14 cores in de C1-DSU, al zouden fabrikanten ook meerdere DSU's kunnen combineren voor socs met meer cores.
:strip_exif()/i/2007721438.jpeg?f=imagenormal)
Naast de SME2-ondersteuning ligt bij de DSU ook de focus op energiebesparingen. Tijdens normale workloads verbruikt de DSU ongeveer 11 procent minder vermogen dan de DSU-120 van vorig jaar. Dat komt door efficiënter beheer van de cache, die sneller in slaapstand gaat. Vorig jaar kreeg de DSU een quicknapfunctie voor het L3-cache, waardoor ongebruikte stukken in een zuinige slaapstand gezet konden worden. Voor de nieuwe C1-DSU zijn de L3-blokjes kleiner opgedeeld, waardoor meer stukjes geheugen vaker en sneller kunnen slapen. Volgens Arm verkeert het geheugen in de DSU-120 tot 53 procent van de tijd in slaapstand, maar door de fijnmaziger opsplitsing in de C1-DSU stijgt dat tot 96 procent. Dat levert een energiebesparing van de cache van 7 procent op.
De overige besparingen zijn onder meer te danken aan een nieuwe topologie van het transportnetwerk. Dat verplaatst data tussen de cpu-cores onderling en de caches en is ook verantwoordelijk voor de communicatie met de SME2-unit(s) in het cpu-cluster. In de C1-DSU zijn minder nodes en dus minder onderlinge verbindingen tussen die nodes dan in de DSU-120, waardoor energie wordt bespaard zonder aan bandbreedte of prestaties in te boeten.
:strip_exif()/i/2007721436.jpeg?f=imagenormal)
Ten slotte laat Arm zien hoe flexibel het cpu-cluster met de C1-DSU is. Alleen de kleinste configuratie met twee Nano-cores heeft geen SME2-ondersteuning, maar alle andere samenstellingen, vanaf vier Nano-cores, wel. De 'flagship'-core bestaat uit twee Ultra-cores, gecombineerd met zes Pro-cores. Iets daaronder gepositioneerd is het 'subflagship' met twee Premium-cores en zes Pro-cores, en fabrikanten kunnen elke gewenste combinatie zelf samenstellen.
System Interconnect
Waar de DSU de verschillende cores onderling en met de caches verbindt, hebben de System Interconnect en system memory management unit (smmu) een andere taak. De System Interconnect en smmu zorgen respectievelijk voor de connectiviteit van de onderdelen binnen de soc en voor toegang tot het geheugen en de beveiliging daarvan.
De System Interconnect is niet langer gescheiden tussen de CI-700, die met het cpu-cluster praat zoals in de vorige generatie, en de gpu's, die met de NI-700 communiceren. De CI-700 en NI-700 communiceerden weer onderling, met het geheugen en met andere soc-onderdelen. In het Lumex-platform communiceren het cpu- én gpu-cluster met de System Interconnect, waarin de systeemcache en network-on-chip geïntegreerd zijn. Daarmee zijn de lijntjes letterlijk korter en hebben ze minder latency: Arm spreekt van een enorme reductie van 75 procent. Die kortere lijntjes zorgen ook voor lagere leakage: vergeleken met de interconnect van vorig jaar (CI-700) is de leakage 86 procent lager.
:strip_exif()/i/2007721528.jpeg?f=imagenormal)
Communicatie met minder omwegen leidt niet alleen tot energiebezuinigingen, maar ook is de cache aangepakt om zowel lagere latencies te hebben als lage lekstromen. De toegang tot de system-level cache (slc) wordt geregeld door twee elementen: de translation buffer unit (tbu) en de translation control unit (tcu). Elk onderdeel binnen de soc communiceert met een of meer tbu's met de systeemgeheugencontroller, en de smmu communiceert weer via tcu's met de cache. Beide zijn met tientallen parameters te configureren voor optimale energiebesparingen en latency's, wat bijdraagt aan een energiebesparing tot 56 procent in de tbu's.
Zo probeert Arm op elke mogelijke plek in de soc energie te besparen en geheugentoegang, zowel tot caches als ram, te optimaliseren. Die geheugentoegang is immers vaak een bottleneck voor veel AI-workloads.
Mali en r.i.p. Immortalis
Naast AI- en cpu-cores blijft Arm ook aan de gpu sleutelen. De reden is simpelweg dat mobile gaming enorm groot is en alleen maar groeit. Volgens cijfers van het bedrijf speelt 83 procent van de mensen weleens spelletjes op draagbare apparaten en komt 48 procent van de inkomsten in de gamingindustrie van mobile gaming. Daarbij baseert Arm zich op data van Newzoo en Sensor Tower, al meldt die eerste dat in 2024 55 procent van de game-inkomsten uit mobile gaming kwam. Hoe dan ook, de markt is er en volgens Arms berekeningen zijn er inmiddels twaalf miljard Arm-gpu's verscheept. Tijd om daar nog een schepje bovenop te doen.
:strip_exif()/i/2007721476.jpeg?f=imagenormal)
In 2022 introduceerde Arm met de G715 de eerste Immortalis-gpu met hardwarematige raytracing. Het jaar erna volgde de Immortalis-G720 en vorig jaar kwam de derde generatie Immortalis uit, met de G925. Dit jaar is Immortalis afwezig en is de naam, net als Cortex, afgeschaft. Alle gpu's zijn weer Mali-gpu's, al is het topmodel in essentie nog wel een Immortalis, met minimaal tien cores en nog steeds raytracing. Wat voorheen de Mali-G725 was, is nu de G1-Premium en de G625 is voortaan de G1-Pro.
Als Immortalis er dan niet meer is, hoe noemt Arm zijn krachtigste gpu's dan? Om in lijn met de nieuwe cpu-cores te blijven, is dat de Mali G1-Ultra geworden. De gpu's zijn nog steeds van de vijfde generatie architectuur, maar dan wel met verbeteringen. Ook hier zijn niet alleen prestaties − zowel voor gaming als AI-workloads − het doelwit, maar ook energiebesparingen, en de Ray Tracing Unit (RTU) is aangepakt.
:strip_exif()/i/2007721482.jpeg?f=imagenormal)
Op het vlak van prestatieverbeteringen zou een gelijkgeconfigureerde gpu gemiddeld 20 procent beter moeten presteren dan een model van vorig jaar. Dat is wel flink afhankelijk van de game, want bij Fortnite is de verbetering 11 procent, terwijl Arena Breakout 26 procent prestatieverbetering kreeg. Daarvoor zijn onder meer verbeteringen in de tiler en in het interne netwerk verantwoordelijk. De tiler kan voortaan dankzij fused primitives twee triangles in plaats van één verwerken en de renderingefficiëntie is verbeterd door betere scheduling van renderingselementen die van elkaar afhankelijk zijn: zo hoeft de shadercore niet zo lang te wachten.
Denk daarbij bijvoorbeeld aan een blur of ander effect van een scène: eerst wordt (een deel van) de scène gerenderd, daarna een blur over de x-as toegepast en daarna een blur op de y-as. Die renderpasses zijn afhankelijk van elkaar, dus moet de gpu wachten tot de ene pass klaar is voordat aan de volgende begonnen kan worden. De shadercores zijn tijdens het opstarten of afronden van die passes echter lang niet optimaal bezet. Door de scène in stukjes op te delen, kunnen regio's die al klaar zijn alvast hun volgende renderpass beginnen, zodat de cores vollediger benut worden.
Het interne netwerk van de gpu heeft dubbel zoveel bandbreedte gekregen als in de vorige generatie en bovendien zijn ook de L2-caches qua afmetingen verdubbeld. De shadercores zitten voortaan per twee in een stack, waardoor ze onderling sneller en efficiënter data kunnen uitwisselen. Ook de registers voor Fast Access Uniform (FAU) zijn verdubbeld, waardoor het ram minder vaak geraadpleegd hoeft te worden; dat levert latencywinst op.
:strip_exif()/i/2007721520.jpeg?f=imagenormal)
Voor AI-workloads is de MMUL.FP16-instructie toegevoegd, waardoor matrixvermenigvuldigingen veel sneller en zuiniger zijn. De meeste AI-berekeningen maken gebruik van vectoren of matrices. Net als voor gaming claimt Arm een verbetering van 20 procent voor AI-workloads. Bij AI op de gpu gaat het bijvoorbeeld om sdr-content converteren naar hdr-beelden of spraakherkenning.
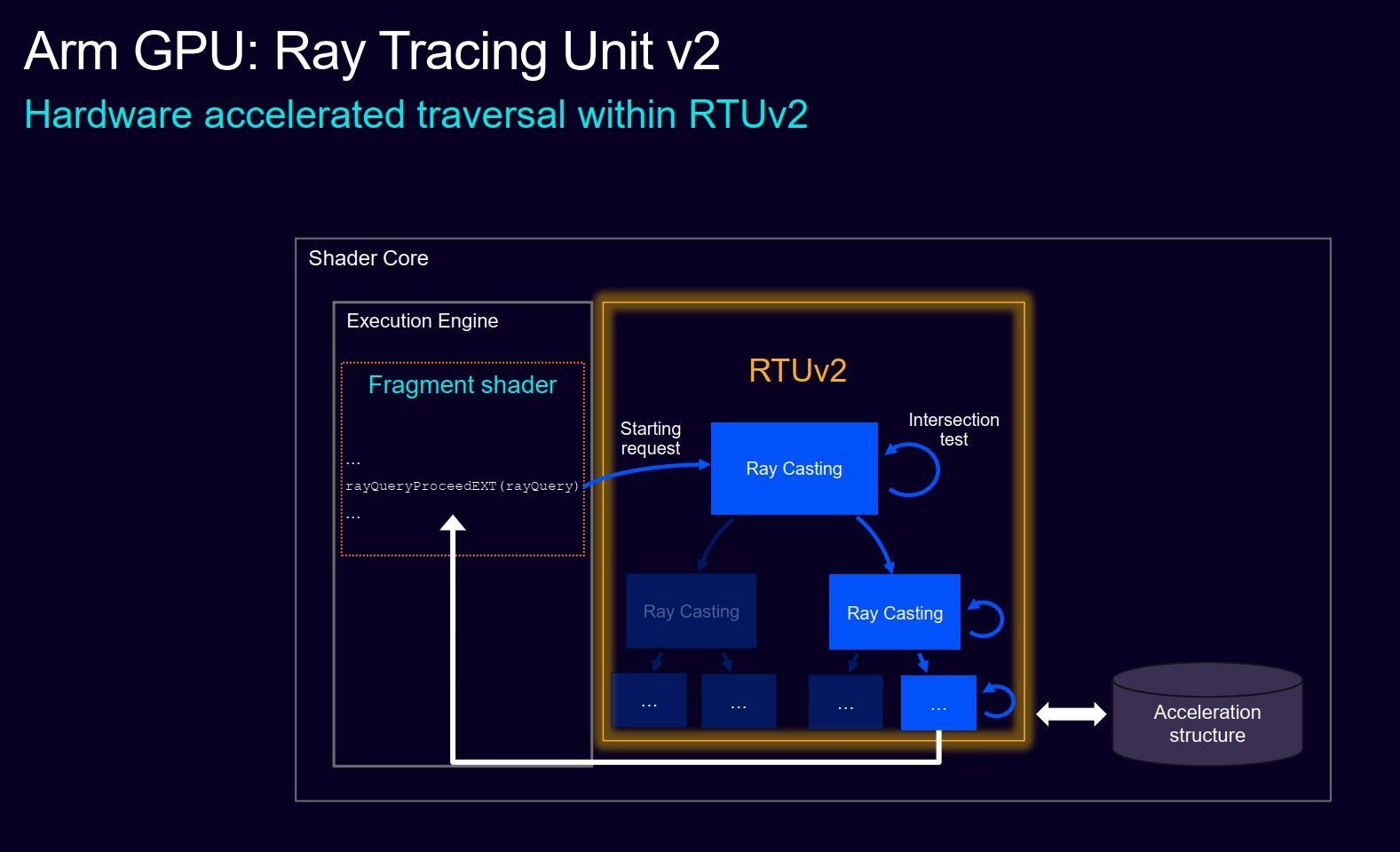
RTUv2
Omdat raytracing steeds meer in mobile gaming gebruikt wordt, mede dankzij het gebruik van desktop-deferred renderengines als Unreal Engine 5, heeft Arm de RTU in prestaties verdubbeld. Daarbij hanteert de nieuwe RTUv2 een nieuw model om individuele rays te berekenen. De oudere RTU's gebruiken packedraymodellen, terwijl RTUv2 een singleraymodel hanteert. Dat moet de complexere belichting van moderne games ten goede komen. De RTUv2 is bovendien nu een standalone-unit, los van de shadercore. De RTU is ook volledig uitschakelbaar, zodat er geen energie wordt verspild als er geen raytracing nodig is.
In een demo met Lumilings (een interne demo met raytracing op basis van de Unreal Engine 5 met shadermodel 5 en Megalight) haalde de oude Immortalis-G915-gpu 26,8fps met hardwareraytracing. Met softwareraytracing − en minder mooie resultaten − haalde die gpu 30,9fps, net boven de 30fps-grens. De nieuwe Mali G1-Ultra haalde 37,5fps met volledige hardwarematige raytracing, een verbetering van 40 procent.
:strip_exif()/i/2007721510.jpeg?f=imagenormal)
Om alle verbeteringen optimaal te benutten, is aan de softwarekant een tile-based hardwarecounter beschikbaar. Die analyseert per deelgebied van een frame of en welke bottlenecks er zijn, zodat ontwikkelaars hun code kunnen optimaliseren om de gpu vollediger te benutten.
Software en platform
Om alle verbeteringen in de gpu zo optimaal mogelijk te benutten, is aan de softwarekant een tile-based hardwarecounter beschikbaar. Die analyseert per deelgebied van een frame of en welke bottlenecks er zijn, zodat developers hun code kunnen optimaliseren om de gpu vollediger te benutten.
De performanceoptimalisatiesoftware voor de gpu is uiteraard lang niet de enige software die Arm voor developers beschikbaar heeft. Het belangrijkste hulpmiddel in Arms arsenaal is KleidiAI, een library om met name AI-workloads te ontwikkelen en optimaliseren voor de Arm-cpu's. KleidiAI krijgt bij de introductie van het Lumex-platform direct ondersteuning voor de nieuwste onderdelen van de Arm-soc, zoals de nieuwe SME2-units. Ook werkt Arm samen met onder meer Google om SME2 niet alleen in Android 16 te ondersteunen, maar ook diverse libraries en codecs, zoals VP9 en libyuv, van de nieuwe mogelijkheden gebruik te laten maken.
Ook met andere partijen, zoals Unreal Engine, Unity, PyTorch en TensorFlow, werkt Arm samen om de Arm-hardware direct optimaal te benutten. Voor optimalisaties heeft Arm overigens nog een nieuwe telemetrietool beschikbaar, die de prestaties van apps kan analyseren, bottlenecks kan aanwijzen en helpt algoritmes te optimaliseren voor het Lumex-platform. Klanten kunnen nu al voor fpga-ontwerpen met de telemetrie aan de slag; voor derden is het als onderdeel van Perfetto (Arms tracetool) later dit jaar beschikbaar.
:strip_exif()/i/2007721542.jpeg?f=imagenormal)
Hardware
Om dat mogelijk te maken, helpt Arm tegenwoordig ook met de hardware-implementatie. Vorig jaar startte Arm daarmee met CSS, waarbij, net als voor de servermarkt, bepaalde componenten van het Arm-portfolio als kant-en-klare bestanden voor foundries beschikbaar zijn. Ook voor Lumex stelt Arm die zogeheten GDSII-bestanden voor een deel van de hardware beschikbaar. Zo zijn de C1-Ultra-cores en de Pro-cores tape-out-klaar beschikbaar, maar de kleinste cores niet. Zo kunnen de kritische cores door Arm zelf geoptimaliseerd worden, zodat klanten optimaal presterende hardware krijgen. Net als de laatste cores zijn de Lumex-cores primair voor het 3nm-procedé gemaakt.
Naast de cores zijn ook de Mali G1-Ultra-gpu's en de slc van de DSU-C1 klaar voor tape-out. De SME2-unit is eveneens beschikbaar als los tape-outbestand. Voor de meeste tests hanteert Arm overigens een referentieplatform dat in fpga gerealiseerd is. Dat referentieplatform is de 'flagship'-configuratie met twee C1-Ultra-cores, zes C1-Pro-cores, een SME2-unit, het C1-DSU met 16MB L3-cache en de 14-core-Mali G1-Ultra met 4MB L2-cache. De System Interconnect heeft 16MB slc-cache, dat overigens ook als GDSII beschikbaar is. Het aangeraden dram is iets sneller dan voorheen: Arm gebruikt lpddr5x-ram van 9600MT/s in plaats van het 8533MT/s van het referentieplatform van de vorige generatie.
Tot slot
Al die hardware-, software- en ontwikkelhulp moet Arm-licentiehouders en IP-klanten in staat stellen zo snel mogelijk producten met de nieuwe generatie hardware op de markt te krijgen. Ter illustratie: 'vroeger' werd MWC in maart als streefdatum aangehouden voor nieuwe telefoons, maar dat is gaandeweg verschoven naar CES en inmiddels is zelfs Singles Day, een overwegend Chinese feestdag op 11 november, het doelwit. Met andere woorden: producten met Lumex zouden al in november aangekondigd kunnen worden.
:strip_exif()/i/2007721556.jpeg?f=imagenormal)
Arm bereidt zich met het Lumex-platform voor op een markt waarin AI niet langer uitsluitend in de cloud draait, maar zich verplaatst naar lokale, 'agentic' AI, die gebruikers niet laat wachten op servers en onafhankelijk is van verbindingen. En wees niet bang: het is niet alleen maar AI dat de klok slaat. Ook aan traditionele apps én gaming is gedacht, en zoals altijd blijft Arm zoeken naar energiebesparingen om je accu ook in je volgende smartphone langer mee te laten gaan.
Redactie: Willem de Moor • Eindredactie: Monique van den Boomen

:strip_exif()/i/2007721558.jpeg?f=imagegallery)
:strip_exif()/i/2007721398.jpeg?f=imagegallery)
:strip_exif()/i/2007721404.jpeg?f=imagegallery)
:strip_exif()/i/2007721410.jpeg?f=imagegallery)
:strip_exif()/i/2007721536.jpeg?f=imagegallery)
:strip_exif()/i/2007721534.jpeg?f=imagegallery)
:strip_exif()/i/2007721532.jpeg?f=imagegallery)
:strip_exif()/i/2007721406.jpeg?f=imagegallery)




:strip_exif()/i/2007721426.jpeg?f=imagegallery)







:strip_exif()/i/2007721526.jpeg?f=imagegallery)
:strip_exif()/i/2007721530.jpeg?f=imagegallery)
:strip_exif()/i/2007721476.jpeg?f=imagegallery)
:strip_exif()/i/2007721482.jpeg?f=imagegallery)
:strip_exif()/i/2007721500.jpeg?f=imagegallery)
:strip_exif()/i/2007721502.jpeg?f=imagegallery)
:strip_exif()/i/2007721508.jpeg?f=imagegallery)
:strip_exif()/i/2007721506.jpeg?f=imagegallery)
:strip_exif()/i/2007721520.jpeg?f=imagegallery)

:strip_exif()/i/2007721540.jpeg?f=imagegallery)
:strip_exif()/i/2007721544.jpeg?f=imagegallery)
:strip_exif()/i/2007721546.jpeg?f=imagegallery)
:strip_exif()/i/2007721542.jpeg?f=imagegallery)
:strip_exif()/i/2007721548.jpeg?f=imagegallery)
:strip_exif()/i/2007721550.jpeg?f=imagegallery)
:strip_exif()/i/2007721552.jpeg?f=imagegallery)
:strip_exif()/i/2007721554.jpeg?f=imagegallery)
:strip_exif()/i/2007721556.jpeg?f=imagegallery)
/i/2008189740.png?f=fpa)
:strip_exif()/i/2007948258.jpeg?f=fpa)
/u/360941/crop57306fdf1185c_cropped.png?f=community)
/u/621775/crop5db181fac9815_cropped.png?f=community)
/u/247151/moppersmurf-60px.png?f=community)
:strip_icc():strip_exif()/u/387110/crop5e74c92f7915a_cropped.jpeg?f=community)
/u/12436/p1_normal.png?f=community)
/u/38782/crop6146c7a29805d_cropped.png?f=community)
:strip_icc():strip_exif()/u/81611/headcrop.jpg?f=community)