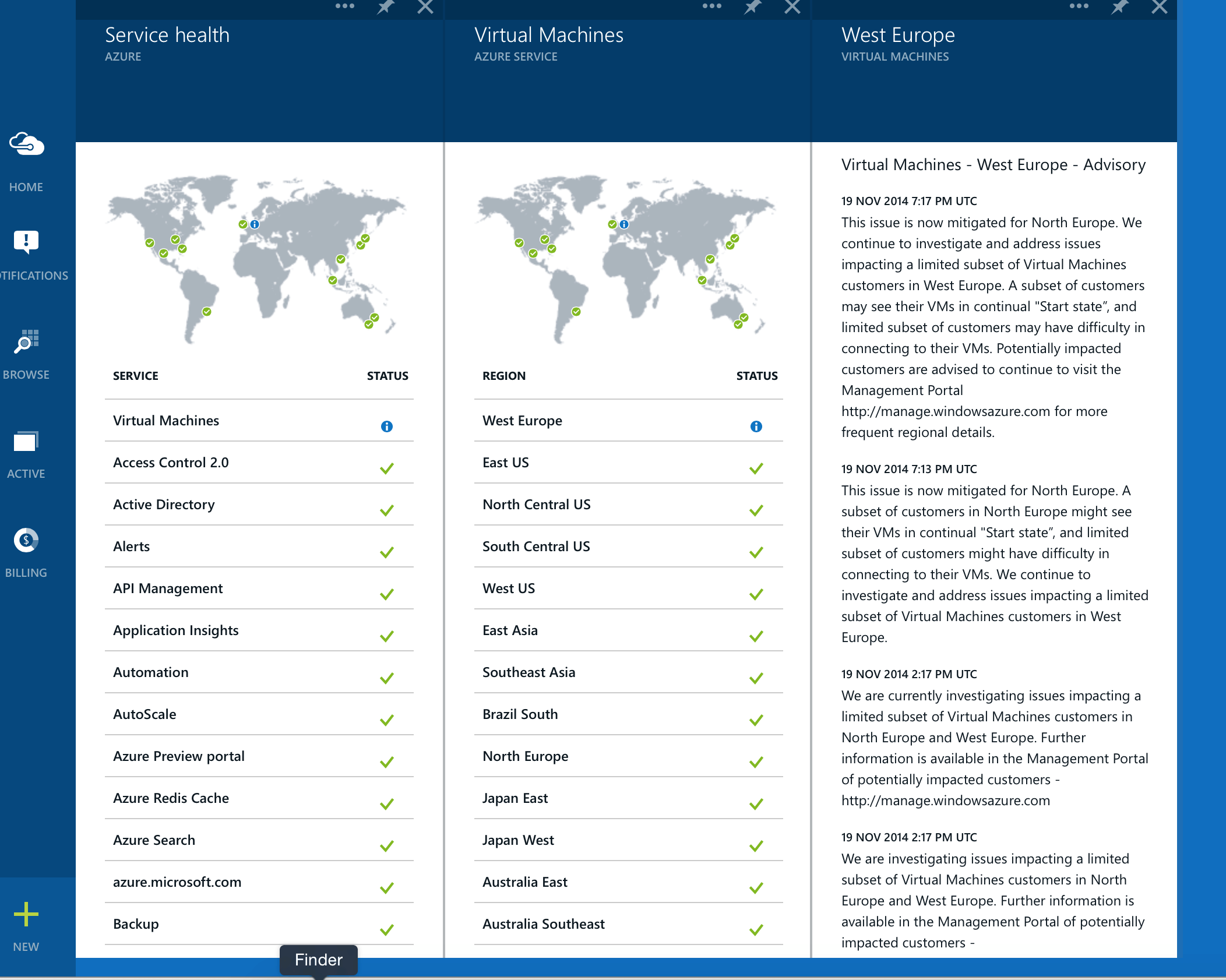
Microsofts clouddienst Azure kampt al de gehele woensdag met een storing. Op het moment van schrijven is die grotendeels opgelost, maar op de Europese servers zijn nog steeds problemen met de bereikbaarheid.
![]() De problemen begonnen in de nacht van dinsdag op woensdag, rond een uur of twee Nederlandse tijd. Vooral kleinere bedrijven lijken last te hebben gehad van de storing, waaronder de Nederlandse thuiszorgorganisatie Viva. Ook een aantal diensten van Microsoft zelf zou echter slecht te bereiken zijn geweest, waaronder Office 365 en Xbox Live, schrijft BBC News.
De problemen begonnen in de nacht van dinsdag op woensdag, rond een uur of twee Nederlandse tijd. Vooral kleinere bedrijven lijken last te hebben gehad van de storing, waaronder de Nederlandse thuiszorgorganisatie Viva. Ook een aantal diensten van Microsoft zelf zou echter slecht te bereiken zijn geweest, waaronder Office 365 en Xbox Live, schrijft BBC News.
Inmiddels zijn de problemen grotendeels opgelost, maar Microsoft waarschuwt dat een deel van de virtuele servers op Noord- en West-Europese servers nog steeds problemen kan hebben. Het is onbekend om hoeveel klanten het precies gaat of wat de oorzaak van de storing is.

/i/2000776373.png?f=fpa)
/i/1225188467.png?f=fpa)
/i/1250240009.png?f=fpa)
:strip_icc():strip_exif()/u/144094/brinkie.jpg?f=community)
:strip_icc():strip_exif()/u/489983/crop5db33928bbeea_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/14/wildhagen60x60.jpg?f=community)
:strip_exif()/u/473463/preloader-w8-cycle-black.gif?f=community)
:strip_icc():strip_exif()/u/20383/crop57de62db41c81.jpeg?f=community)
:strip_icc():strip_exif()/u/76569/garfield14.jpg?f=community)
/u/62673/crop56e2e8ee04df2_cropped.png?f=community)
:strip_icc():strip_exif()/u/6764/cergorach.jpg?f=community)
/u/107495/godzilla%252060x60.png?f=community)
/u/23785/crop5dcd5c59e07f9.png?f=community)
:strip_icc():strip_exif()/u/10917/crop562b75f07b9fd_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/208430/3f5a00acf72df93528b6bb7cd0a4fd0c.jpeg?f=community)
/u/85011/crop65747d648e683_cropped.png?f=community)
:strip_exif()/u/16838/usericon.gif?f=community)
:strip_icc():strip_exif()/u/122857/Ed.jpg?f=community)
/u/478774/60x60.png?f=community)
/u/122874/crop5e26d7a209cd1_cropped.png?f=community)
:strip_exif()/u/290839/crop5b757283a589c_cropped.gif?f=community)
:strip_icc():strip_exif()/u/338167/Spiralboxes_60x60.jpg?f=community)
:strip_exif()/u/133150/pixar_bird_static.gif?f=community)
:strip_icc():strip_exif()/u/186602/Genetai_Steam%2520_klein.jpg?f=community)
:strip_icc():strip_exif()/u/37911/zlao.jpg?f=community)
:strip_exif()/u/406467/crop5cc36e51b303a_cropped.gif?f=community)
{kind=link}