Amerikaanse en Zweedse taalwetenschappers zijn erin geslaagd een versleuteld document uit het einde van de 18e eeuw te ontcijferen. De makers van het Copiale Cipher maakten gebruik van de lastig te ontcijferen homofone substitutie-techniek.
Het Copiale Cipher is een document van 105 pagina's met 75.000 karakters, die eind 18e eeuw opgetekend zijn. Het manuscript bestaat uit onbekende abstracte symbolen, afgewisseld met Latijnse karakters. De naam komt van een van de slechts twee annotaties in klare tekst. Het document werd ontdekt in een archief van een instituut in het voormalige Oost-Berlijn en is nu in particuliere handen.
De Amerikaanse computerwetenschapper Kevin Knight van het Information Sciences Institute van de University of Southern California begon dit jaar samen met taalwetenschappers Beata Megyesi en Christiane Schäfer van de Zweedse Uppsala-universiteit aan de ontcijfering van de eerste 16 pagina's.
De code bleek via homofone substitutie omgezet te zijn, waarbij een alfabetletter in verschillende karakters kan worden omgezet, waardoor het moeilijk is de klare tekst via analyse van de frequentieverdeling te ontrafelen. Ook werden de onderzoekers aanvankelijk op een dwaalspoor gezet door de Latijnse letters, waarvan ze dachten dat het zogenoemde nulls waren, die verder geen betekenis hadden. De wetenschappers wisten uiteindelijk de ingang te vinden door ervan uit te gaan dat de oorspronkelijke taal Duits was en de tekens met een circumflex voor dezelfde letter stonden. De Latijnse karakters bleken voor spaties te staan. Het team beschrijft de ontcijfering in het document The Copiale Cipher.

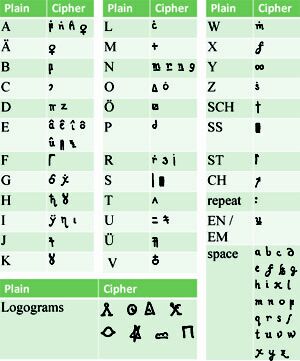
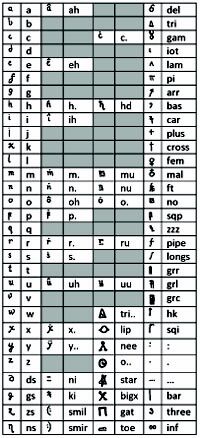
De ontcijferde tekst had betrekking op de rituelen en politieke verwikkelingen van een Duits geheim genootschap. "Historici geloven dat geheime genootschappen een rol speelden bij revoluties, maar veel hierover is onduidelijk, mede omdat veel documenten versleuteld zijn", zegt Knight.
![]() Helaas!
Helaas!
De video die je probeert te bekijken is niet langer beschikbaar op Tweakers.net.

:strip_exif()/i/1294081930.gif?f=fpa)
/u/26227/amdklein.JPG?f=community)
/u/96903/cdwaveicon.png?f=community)
/u/354442/FSJALSMALL.png?f=community)
/u/122416/SCSI.JPG?f=community)
:strip_exif()/u/7759/red_cat.gif?f=community)
/u/129550/crop56f4f43ec16da.png?f=community)
/u/62384/crop61891f444d6e9.png?f=community)
/u/27299/hoofd.png?f=community)
:strip_icc():strip_exif()/u/217667/crop5a142ffc7e48c_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/3350/crop56ab6efb84b85_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/72351/Toon_en_Len%25202015-02-02%252070x69.jpg?f=community)
:strip_icc():strip_exif()/u/2244/crop68625f327087c_cropped.jpg?f=community)
:strip_exif()/u/634/crop56eab269d97ab.gif?f=community)
:strip_icc():strip_exif()/u/218679/Michael_Melgar_LiquidArt_resize_droplet.jpg?f=community)
:strip_icc():strip_exif()/u/272893/Pingu-Waving.jpg?f=community)
:strip_icc():strip_exif()/u/79859/crop562e258ce2088_cropped.jpeg?f=community)
:strip_icc():strip_exif()/u/212466/firefox-vs-internet-explorer.jpg?f=community)