Google geeft Chrome op Android de functie om webpagina's samen te vatten en te beluisteren als interactief gesprek tussen twee AI‑stemmen. Die functie zat al in NotebookLM voor eigen documenten, maar zit nu ook in de browser.
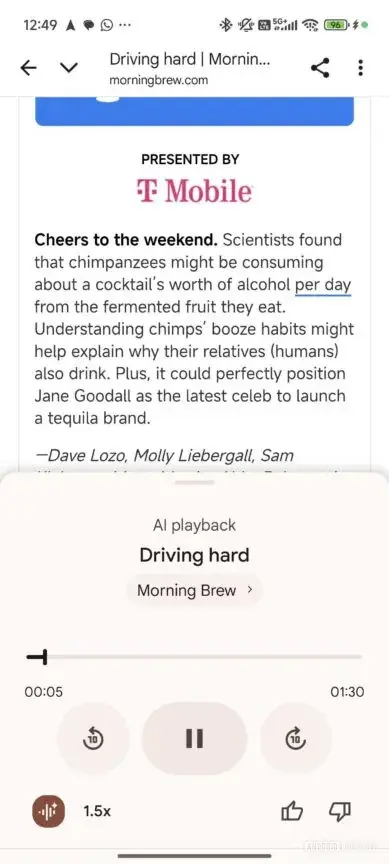
De functie heet 'listen to this page' en is te vinden in het menu van de browser, meldt Android Authority. Die vond de functie in de stabiele versie van de browser, versie 140.0.7339.124. Het is mogelijk dat het bij veel meer mensen werkt, maar de functie lijkt in elk geval nog niet bij iedereen aan te staan. Het is onbekend of het direct in het Nederlands werkt.
'Listen to this page' kan de pagina integraal voorlezen, maar heeft ook de mogelijkheid om een samenvatting te laten bespreken door twee AI-stemmen in een podcastformat. Dat is bedoeld om de audio korter en beter behapbaar te maken. De functie lijkt op de Audio-overzichten in Google-tool NotebookLM. Die verwerken eigen documenten tot een podcast met twee AI-stemmen.

:fill(white):strip_exif()/i/2002189289.jpeg?f=thumbmedium)
/i/2005017354.png?f=fpa)
:strip_exif()/i/2006285086.jpeg?f=fpa)
/i/2007686288.png?f=fpa)
/i/2007689270.png?f=fpa)
:strip_exif()/u/99904/4100363.gif?f=community)
:strip_icc():strip_exif()/u/270010/user.jpg?f=community)
/u/1042525/crop5f26a11f70624_cropped.png?f=community)
/u/12436/p1_normal.png?f=community)
/u/244207/crop5c38ae2351fe1.png?f=community)
/u/63756/rtg_final.JPG?f=community)
:strip_exif()/u/24150/crop5981a08dd11cd_cropped.gif?f=community)
:strip_icc():strip_exif()/u/277895/crop5eda5f3273e75_cropped.jpeg?f=community)
/u/587794/crop67ed38838b6e6_cropped.png?f=community)
:strip_exif()/u/79762/got.gif?f=community)