Loadbalancing in het algemeen
 Wat houdt loadbalancing in? Loadbalancing betekent heel letterlijk het verdelen van werk over meerdere uitvoerenden. In praktijk houdt dat voor Tweakers.net in dat wij de binnenkomende requests (opdrachten van bezoekers om pagina's te genereren) voor de verschillende websites verdelen over het serverpark. Dat dit een groot aantal voordelen heeft hoeven wij je waarschijnlijk niet te vertellen, maar toch noemen wij een aantal redenen die voor ons van belang waren:
Wat houdt loadbalancing in? Loadbalancing betekent heel letterlijk het verdelen van werk over meerdere uitvoerenden. In praktijk houdt dat voor Tweakers.net in dat wij de binnenkomende requests (opdrachten van bezoekers om pagina's te genereren) voor de verschillende websites verdelen over het serverpark. Dat dit een groot aantal voordelen heeft hoeven wij je waarschijnlijk niet te vertellen, maar toch noemen wij een aantal redenen die voor ons van belang waren:
- Als er een server uitvalt wordt dat opgevangen door de andere servers uit de groep servers (de serverpool). Hetzelfde geldt uiteraard voor servers die vanwege onderhoudsredenen worden platgelegd.
- Indien een bepaalde website ineens heel zwaar belast wordt staan de andere servers klaar om die verzwaring samen op te vangen. Zonder loadbalancing zou één server op eigen houtje alle extra aandacht moeten verwerken, iets wat meestal resulteert in een niet bereikbare site.
Loadbalancing wordt dus meestal om twee redenen toegepast; het verdelen van de werklast en het verlagen van het aantal 'Single Point of Failures'.
 Hoe doet Tweakers.net dat op dit moment?
Hoe doet Tweakers.net dat op dit moment?
Momenteel proberen we de websites zo goed mogelijk te verdelen over de servers, rekening houdend met de zwaarte van de verschillende onderdelen. De frontpage wordt door middel van een zogenaamde 'round robin DNS' verdeeld over verschillende webservers. Dit betekent dat er meerdere servers zijn die reageren op de naam www.tweakers.net, omdat de DNS-server instructies heeft om het IP-adres van een willekeurige server uit de groep terug te geven wanneer iemand om de naam www.tweakers.net vraagt. Het nadeel van deze methode is vrij makkelijk te zien; als er een server uitvalt zal een deel van de requests niet afgehandeld worden omdat de DNS-server niet controleert of een bepaalde server wel online is. Stel dus dat één van de drie servers uitvalt, dan komt een derde van de bezoekers bij een dode server uit. Ook een nadeel is dat de DNS server niet kan zien hoeveel werk de servers hebben, hierdoor kan het nog steeds voorkomen dat een server, die te veel werk heeft, aangesproken wordt.
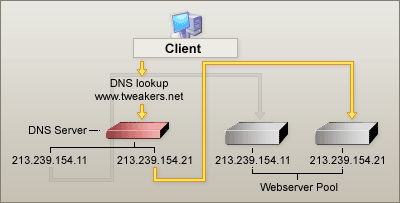
Enkele andere manieren van loadbalancing
Naast de vrij primitieve 'round robin'-methode is het ook mogelijk om een speciale server in te zetten als 'front-end'. Deze vangt dan alle connecties op en stuurt deze door naar één van de servers uit de serverpool. De zogenaamde 'virtual server' software voor Linux is een voorbeeld van een pakket dat dit kan regelen. Net toen we bezig waren om een dergelijke constructie te implementeren werden we benaderd door BrainForce, met de vraag of we niet toevallig interesse hadden om de nieuwe One4Net B-100 opstelling uit te proberen.

Uiteraard zijn er nog vele andere manieren van loadbalancing, zo zijn er een aantal softwarematige methoden. Een ervan is het inzetten van een reverse-proxy met bijvoorbeeld Squid. Deze methode kan weliswaar een verdeling maken van de load, maar heeft geen mogelijkheden voor failover als de load balancer of één van de webservers uitvallen. Verder zijn er modules voor Apache zoals mod_backhand, maar hoewel dit best aardig werkt hou je natuurlijk een 'Single Point of Failure'.
Er zijn natuurlijk ook vele hardwarematige oplossingen. De zelfbouw Linux Virtual Server systemen, die we al eerder hebben genoemd, beschikken wel over failover en high availability features voor zowel de loadbalancers als de webservers. De hardwarematige oplossingen van bedrijven als Cisco, BigIP en Foundry Networks hebben als voordeel dat zij snel geïmplementeerd kunnen worden, veel mogelijkheden hebben en gebruiksvriendelijk zijn. Helaas zijn deze loadbalancers erg duur. Denk hierbij aan bedragen van 10.000 tot soms wel 25.000 dollar.
Tweakers.net en BrainForce
Waarom de keus voor BrainForce
De One4Net B-100 van BrianForce is een machine die in principe precies kan doen wat we zelf wilden maken, maar dan als kant-en-klare oplossing. Het product bestaat uit een speciaal getweakte Linux-kernel en met zorg geselecteerde hardware; een erg interessante optie voor een site als deze die zo'n 1,2 miljoen views per dag moet afhandelen. Voor een snelle verwerking van de requests staat een 800MHz Pentium III met 256MB RAM garant. Tweakers.net heeft daarom nu beschikking over twee van deze loadbalancers in speciale HA uitvoering. Hierbij staat HA voor High Availability, een logische keuze vanwege de vele tweakotine-junks, en twee stuks om te voorkomen dat een probleem met een loadbalancer meteen de hele site onbereikbaar maakt. Omdat BrainForce een relatief kleine speler in deze markt is kunnen ze goedkope producten aanbieden. Bovendien luisteren ze goed naar onze ideeën en denken ze mee in het geval van problemen. Zo heeft een medewerker uit Duitsland in de eerste week uitleg gegeven over 'Zhe Guichi'  , en is Kees daarna nog diverse malen naar TrueServer geweest om samen met BrainForce een goed begrip te krijgen van de werking van het systeem.
, en is Kees daarna nog diverse malen naar TrueServer geweest om samen met BrainForce een goed begrip te krijgen van de werking van het systeem.
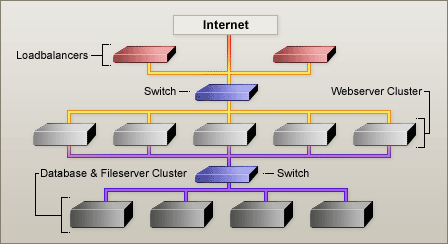
Samenwerking met BrainForce
De One4Net loadbalancers die we ontvingen hadden pas het laatste stadium van de bèta-periode bereikt, en waren nog niet helemaal klaar voor productie. Toch besloten we ze al in te gaan zetten, om alvast ervaring op te kunnen doen en waar mogelijk feedback te geven om het product verder te verbeteren. Een deel van de door ons aangedragen suggesties zijn inmiddels ook daadwerkelijk in de software doorgevoerd. De belangrijkste verbeteringen zijn de volgende:
- De GUICC (Graphical User Interface Control Centre) beheerssoftware is grotendeels in Java geschreven en zou in theorie dus op ieder besturingssysteem moeten draaien. Toch bleek het nog niet helemaal lekker te lopen buiten het ontwikkelplatform (SuSe). Na enkele aanwijzingen wisten de mensen van BrainForce deze problemen op te lossen, waardoor de software nu op veel meer - zoniet alle - Linux versies werkt.
- De GUICC interface kon geen contact leggen met de B-100 als software en loadbalancer niet in hetzelfde subnet zaten. Ook dit euvel is nu opgelost, waardoor de loadbalancers nu ook van buitenaf beheerd kunnen worden.
- Volledige ondersteuning voor NAT is ook naar aanleiding van problemen die we ontdekten geïmplementeerd. Toen de loadbalancers pas in gebruik waren genomen kwamen we tot de conclusie dat dit nog niet helemaal werkte, waardoor bijvoorbeeld de passmailer de buitenwereld niet kon bereiken.
Wij zijn echter niet de eersten die met deze loadbalancers werken. Een goed voorbeeld van een site die al sinds november met de B-100 werkt is Foto Keller in Duitsland. De loadbalancer daar is nog niet down geweest.
De One4Net B-100 in detail
De bedieningsinterface
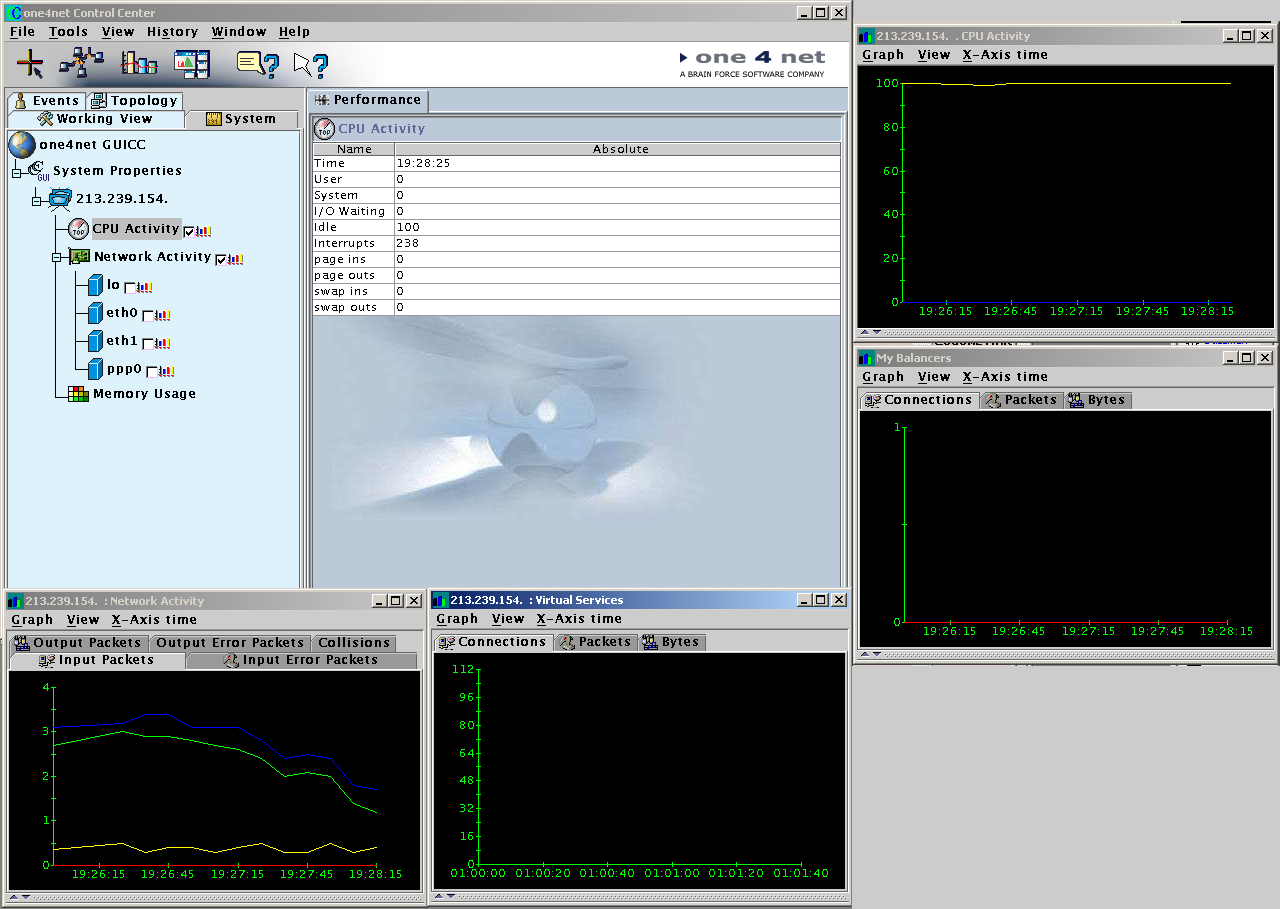
Voor het beheer van de loadbalancers is er de GUICC (Graphical User Interface Control Center), waarmee de loadbalancers remote bediend kunnen worden. Om te bekijken hoe stabiel het netwerk draait kunnen er via de GUICC ook allerlei statistieken opgevraagd worden over zaken als uptimes en serverbelasting. Deze gaan we proberen te integreren in de statistieken-pagina van Tweakers.net.

De interface bij binnenkomst

Allerlei interessant uitziende grafiekjes met statistieken

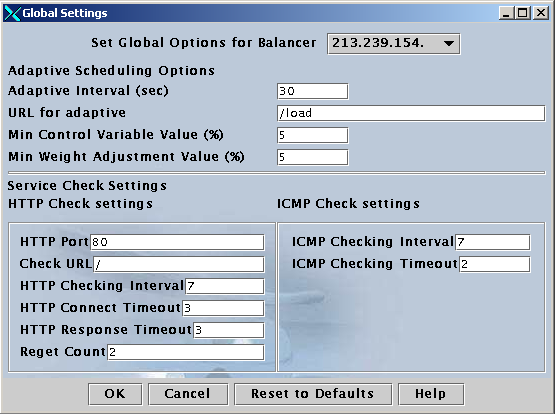
Globale instellingen voor loadbalancing

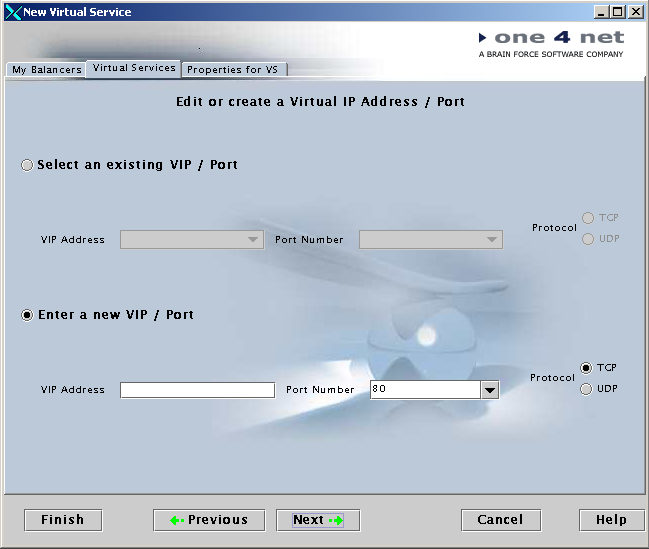
Aanmaken nieuwe virtual-service

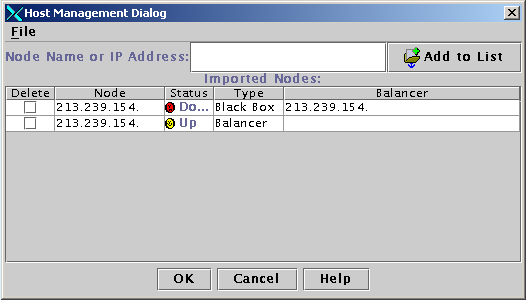
Overzicht van de hosts
Wat kunnen de One4Net loadbalancers allemaal?
Ondanks de beta-versie van de software zijn we van mening dat we de loadbalancers erg goed kunnen gebruiken. Niet alleen zijn ze makkelijk in gebruik, maar ook nog eens speciaal geoptimaliseerd voor het werk dat ze moeten doen. De B-100 kent vijf verschillende manieren om de aanvragen over verschillende servers te verdelen:
- Round Robin: simpelweg 'één voor één' de verschillende servers een verbinding doorgeven.
- Weighted Round Robin: ongeveer hetzelfde als de normale Round Robin, maar de servers met een hogere 'weight' krijgen meer verbindingen te verwerken. Zo kun je bijvoorbeeld aangeven dat een dual bak twee keer zoveel werk krijgt als een andere server met één processor.
- Least Connection: als er grote verschillen zijn in de tijdsduur van het verwerken van een request kan het zijn dat 'Round Robin' niet goed meer werkt. Least Connection geeft de server die het minste verbindingen open heeft staan het meeste werk.
- Weighted Least Connection: zie Least Connection, maar dan weer met de mogelijkheid om aan te geven dat een bepaalde server zwaarder belast kan worden dan een andere.
- Adaptive weighted method: de servers bepalen zelf hoe zwaar ze belast kunnen worden. Dit kan afhankelijk zijn van verschillende factoren zoals hoeveelheid vrije schijfruimte, aantal openstaande verbindingen, beschikbare bandbreedte, hoeveelheid vrij geheugen en gebruik van de CPU.
De beveiliging tegen uitval en downtime.
De loadbalancer merkt zelf op dat er een server uitvalt en schrapt deze dan uit het lijstje van beschikbare servers. Mocht het nodig blijken, dan kunnen alle verbindingen doorgesluisd worden naar een enkele server. Ondanks het feit dat de One4Net B-100 gebruik maakt van CompactFlash in plaats van een harde schijf en volledig gebaseerd is op robuuste IBM hardware en Linux software kan het voorkomen dat een loadbalancer uitvalt. Ook hier is bij de B-100 rekening mee gehouden. De twee loadbalancers hebben dezelfde configuratie-files aan boord en houden deze synchroon middels een null-modem kabel. Zodra één van de twee merkt dat de ander niet meer reageert worden direct alle taken naar de overgebleven balancer geschoven.
Er kan echter een vertraging van (nu nog) 30 seconden optreden als de reserve-balancer standby was op het moment dat de primaire uitviel. Dit komt omdat interne en externe IP-adressen moeten worden overgenomen, en deze door de werking van de ethernet-standaard niet van het ene op het andere moment kunnen overspringen. Zodra de uitgevallen loadbalancer weer online komt zal deze in standby modus gaan en netjes zijn broertje beginnen te monitoren, waarna het bovenstaande proces zich eventueel weer kan herhalen. Gelukkig is dit 'probleem' grotendeels opgelost in de nieuwe software; de 30 seconden is een standaard instelling die getuned kan worden, en in de nieuwe software is deze instelling standaard op 4,5 seconde gezet.
Laatste woord
Nu denk je misschien: "wat een raar einde voor dit verhaal". Dat klopt, omdat we nog bezig zijn met nieuwe software en het configureren van de apparaten is het op dit moment lastig om een echte conclusie te trekken, maar Tweakers als we zijn willen we jullie graag op de hoogte houden  . Als we de One4Net B-100 apparaten in gebruik hebben genomen zal er een tweede artikel verschijnen.
. Als we de One4Net B-100 apparaten in gebruik hebben genomen zal er een tweede artikel verschijnen.

:strip_icc():strip_exif()/u/21/crop69f04ee6196b5_cropped.jpg?f=community)
/u/1830/acm.png?f=community)
:strip_icc():strip_exif()/u/4738/crop61e94d5cc0eac.jpg?f=community)
:strip_exif()/u/19605/nessie9kb.gif?f=community)
/u/3106/crop601874b34ff83_cropped.png?f=community)
/u/1/femme.png?f=community)
/u/8/oog3.png?f=community)
:strip_exif()/u/2172/crop57acf4ac04e70.gif?f=community)
:strip_icc():strip_exif()/u/1740/shark.jpg?f=community)
/u/1056/crop68274afe18332_cropped.png?f=community)
:strip_icc():strip_exif()/u/3370/Infinity.jpg?f=community)
:strip_icc():strip_exif()/u/27572/crop5d5fa7a843673_cropped.jpeg?f=community)
/u/400/defember100.png?f=community)
:strip_exif()/u/8178/hitchhikersguidethemoviesmall.gif?f=community)
/i/1022067132.jpg?f=imagegallery){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}