Inleiding
 De release van Intel's 64 bit Itanium processor komt steeds dichterbij, zeer binnenkort zullen we de pilot release van 733 en 800MHz systemen zien. Intel is echter altijd nogal geheimzinnig gebleven over de performance van de chip en de weinige machines die op dit moment zijn uitgeleend aan softwareontwikkelaars worden zwaar bewaakt, niet alleen fysiek, maar ook door te dreigen met rechtszaken in non-disclosure agreements. Maar als Tweakers zijn wij natuurlijk nieuwsgierig naar de Itanium. Wat is het voor een processor? Waarom is Intel er zo lang mee bezig geweest? Wat zijn de toekomstplannen ervoor?
De release van Intel's 64 bit Itanium processor komt steeds dichterbij, zeer binnenkort zullen we de pilot release van 733 en 800MHz systemen zien. Intel is echter altijd nogal geheimzinnig gebleven over de performance van de chip en de weinige machines die op dit moment zijn uitgeleend aan softwareontwikkelaars worden zwaar bewaakt, niet alleen fysiek, maar ook door te dreigen met rechtszaken in non-disclosure agreements. Maar als Tweakers zijn wij natuurlijk nieuwsgierig naar de Itanium. Wat is het voor een processor? Waarom is Intel er zo lang mee bezig geweest? Wat zijn de toekomstplannen ervoor?
De antwoorden op een aantal van deze vragen zijn inmiddels op internet te vinden, omdat er al vele documenten en presentaties van Intel en HP te downloaden zijn. Wat echter nog bijna niemand weet is hoe snel hij precies is...
Tweakers.net kreeg enige tijd geleden de kans om een Itanium systeem van dichtbij te bekijken en dat konden we uiteraard niet laten schieten. Daniël en Wouter reisden daarom uitgerust met benchmarksoftware en laptops af naar een geheime locatie ergens in Europa om een aantal tests uit te voeren. Door het lezen van deze sneak preview zul je de antwoorden vinden op de vragen die voorheen alleen bekend waren bij een select groepje softwareontwikkelaars, HP en Intel zelf.
 Een stukje geschiedenis:
Een stukje geschiedenis:
Voor we over gaan naar de benchmarks volgen eerst een paar pagina's met uitleg over de processor zelf. De Itanium is namelijk niet de zoveelste opgevoerde Pentium Pro, maar een van de grond af opnieuw ontworpen 64 bit processor. 64 bit processors zijn niets nieuws, al in 1992 kwam Digital met de 100MHz Alpha 21064, snel gevolgd door Sun, IBM en HP. Intel vond echter dat de tijd nog lang niet rijp was voor 64 bit processors, de voordelen wogen niet op tegen de nadelen en extra ontwerpkosten, het was voor die tijd gewoon complete overkill. Intel besloot daarom te wachten en van haar 64 bit processor iets moois te maken, iets nieuws.
 Zes jaar geleden begon Intel aan een ambitieus project in samenwerking met HP. Het management had namelijk besloten dat ze niet alleen gingen overstappen naar 64 bit, maar ook een compleet nieuwe architectuur gingen invoeren. In 1994 werd daarom begonnen aan het Intel's grootste project ooit. Het doel: het ontwerpen van een nieuwe 64 bit architectuur, de grootste vooruitgang in processortechnologie sinds de 386. Het budget: miljarden guldens.
Zes jaar geleden begon Intel aan een ambitieus project in samenwerking met HP. Het management had namelijk besloten dat ze niet alleen gingen overstappen naar 64 bit, maar ook een compleet nieuwe architectuur gingen invoeren. In 1994 werd daarom begonnen aan het Intel's grootste project ooit. Het doel: het ontwerpen van een nieuwe 64 bit architectuur, de grootste vooruitgang in processortechnologie sinds de 386. Het budget: miljarden guldens.
De ontwerpers van Intel en HP hadden een ongekende vrijheid gekregen, alle belangrijke nieuwe ideeën om een snelle efficiënte processor te ontwerpen die waren ontstaan in tientallen jaren ervaring konden worden toegepast. Normaalgesproken was het toepassen van revolutionaire ideeën vrijwel onmogelijk omdat een belangrijke eis van een nieuw ontwerp backwards compatibility was. Dat is handig voor de gebruiker, maar niet voor ontwerpers. Hoe hoger de snelheden werden en hoe meer features moesten worden ingebakken, hoe meer problemen men tegen kwam met het steeds meer antiek wordende IA-32 architectuur.
Waarom een nieuwe architectuur?
Na dertien jaar trouwe dienst in alle processors van de 386 tot de Pentium 4 is IA-32 toe aan vervanging. Deze architectuur valt onder het zogenaamde CISC (Complex Instruction Set Computing), een methode van werken waarbij de processor meestal een groot aantal verschillende instructies kent. Omdat de processor natuurlijk niet echt zoveel verschillende dingen kan doen hebben CISC processors intern vaak een RISC (Reduced Instruction Set Computing) ontwerp, oftewel proberen ze van binnen meestal met zo min mogelijk verschillende instructies werken. Omdat de processor intern heel anders in elkaar zit dan hij voor de software in elkaar lijkt te zitten moet er van alles heen en weer vertaald worden. Dat is natuurlijk niet erg makkelijk en daaraan is dan ook te merken dat IA-32 zijn beste tijd gehad heeft.
Enkele problemen van nu:
Een processor heeft aan aantal execution units die verantwoordelijk zijn voor het rauwe rekenwerk. Andere delen van de CPU zorgen ervoor dat er opdrachten en gegevens worden aangevoerd en er resultaten worden afgevoerd. Om het maximale uit een processor te halen is het dus noodzakelijk om de execution units continu van data en opdrachten te voorzien. Dit lijkt niet zo ingewikkeld, maar het vereist nogal wat voorzichtigheid, want hoewel de instructies altijd keurig op een rijtje in het geheugen staan komt het slechts zeer zelden voor dat een programma ze exact in die volgorde uitvoert. Sommige opdrachten mogen namelijk alleen worden uitgevoerd als aan bepaalde voorwaarden is voldaan en soms moet er een keuze gemaakt worden tussen twee functies afhankelijk van het resultaat van de vorige.
Om het nog eens extra lastig te maken werkt de processor met een pipeline. Vooraan in de pipeline vliegen instructies naar binnen en na een ritje door het binnenste van de processor wordt het resultaat op de juiste plek neergezet. Omdat het parcours lang is kunnen er meerdere instructies tegelijk doorheen fietsen. Zolang alles op volgorde gaat is dit geen probleem, maar als het programma bij een zogenaamde branch (vertakking) in de code komt moet er dus eerst gewacht worden op het resultaat van opdracht A voordat de processor weet of opdracht B of opdracht C de pipeline in moet. Dat is vervelend, want zoals we al gezegd hebben moeten de execution units zoveel mogelijk gevuld blijven en zolang er niets de pipeline wordt ingegooid staan die dingen maar een beetje uit hun neus te vreten.
Een oplossing daarvoor is om op het moment dat er zo'n branch optreedt te kijken naar de andere opdrachten die in het cache staan te wachten om te worden uitgevoerd. Als daar opdrachten tussen zitten die niets te maken hebben met de opdrachten die staan te wachten op antwoord en dus de loop van het programma niet in de war kunnen gooien worden deze alvast uitgevoerd. Deze manier van werken heet ook wel OOO of Out Of Order execution. Het voordeel daarvan is dat de execution units toch nog iets te doen hebben, maar natuurlijk kost het uitzoeken van geschikte opdrachten ook nogal wat tijd, in sommige gevallen meer dan het kost om even te wachten. Daarom is er nog iets anders bedacht; gokken.
Natuurlijk zijn daarvoor zeer effectieve stukjes hardware en statistische algoritmes, oftewel branch predictors, bedacht die meer dan 95% van de branches goed kunnen voorspellen. De keren dat het fout gaat is het echter een kleine ramp voor de processor. Stel dat de uitslag van opdracht A bepaalt of opdracht B of E moet worden uitgevoerd. De branch predictor gokt op B en voert A, B, C en D de pipeline in. Zodra A er aan de achterkant uitkomt blijkt echter dat E moest worden gedaan. Op dat moment moeten de effecten van B, C en D ongedaan gemaakt worden, iets wat flink kloktikken kost. Pas zodra de pipeline weer leeg is (flushed) en de waarden zijn hersteld worden E, F en G ingevoerd. Aan deze mis-predictions is helaas niets te doen en met de steeds langer wordende pipelines van tegenwoordig is het een steeds groter probleem aan het worden.
Een ander groot nadeel van IA-32 is het feit dat er te weinig registers zijn; kleine stukjes geheugen op de CPU nog sneller dan het L1 cache. Daardoor is de schaalbaarheid van de processors beperkt, zo kunnen er bijvoorbeeld nooit op een efficiënte manier meer dan drie opdrachten per kloktik worden worden verwerkt door een IA-32 processor. Ook de 32 bit beginnen een beetje krap te worden, indien men met extreem grote bestanden wil omgaan of grote hoeveelheden geheugen wil aanspreken zullen 32 bit processors het laten afweten. Dat is op dit moment nog niet zo ter sprake, maar met de snelle groei van informatietechnologie zal het niet lang meer duren voor het een serieuze bottleneck wordt.
EPIC: de oplossing
De nieuwe architectuur moest deze problemen voor een groot deel oplossen, daarnaast moest hij geschikt zijn om zo'n 25 jaar mee te gaan en de schaalbaarheid moest goed zijn. Al snel werd daarom besloten dat de nieuwe standaard gebaseerd moest worden op EPIC: Explicitly Parallel Instruction set Computing. De ideeën daarachter zijn ontstaan rond 1980 en draaien vooral om het parallel uitvoeren van instructies en het zo efficiënt mogelijk gebruik maken van de beschikbare execution units. Een EPIC architectuur is daarom ideaal om de problemen, die op de vorige pagina werden beschreven, op te lossen.
Het is voor een processor ondoenlijk om te bepalen welke instructies elkaar beïnvloeden. De compiler, het programma dat van programmeertaal machinecode maakt, heeft echter alle tijd van de wereld. De letter 'e' in EPIC staat voor Explicity en dat betekent dat het programma aan de processor vertelt welke delen tegelijk (parallel) kunnen worden uitgevoerd. Een EPIC compiler heeft daarom ook veel meer verantwoordelijkheden dan een x86 compiler. Het is zijn taak om de programmacode grondig te analyseren, te bepalen waar vertakkingen optreden en uit te zoeken welke stukken code tegelijkertijd uitgevoerd kunnen worden.
De compiler kan er natuurlijk niet voor zorgen dat er continu code is om te verwerken en dus zullen ook EPIC processors last hebben van branches. EPIC lost dit op door middel van predication. De processor zet dus niet al z'n geld op één keuze, maar verwerkt beide mogelijkheden tegelijk, zodra bekend wordt welk pad het goede was wordt het andere stopgezet. Stel dat de uitslag van opdracht A bepaald of opdracht B of E moet worden uitgevoerd. In plaats van te gokken worden A, B, C, D, E, F en G de pipeline in gegooid. Zodra A er aan de achterkant uitkomt blijkt dat E de goede opdracht was. Op dat moment wordt het uitvoeren van B, C en D stopgezet en de waarden die uit E, F en G komen worden op de goede plaatsen neergezet. Was echter B, C en D de goede weg geweest had dat geen kloktik meer of minder gekost. De enorme klap van het misgokken wordt hiermee verbannen.
Het kan natuurlijk ook gebeuren dat er tijdelijk geen opdrachten kunnen worden uitgevoerd omdat er gegevens uit het cache, het RAM, of in het ergste geval de harde schijf nodig zijn. EPIC probeert de wachttijden te minimaliseren door middel van speculation. Dit houdt in dat de processor voor hij de gegevens daadwerkelijk nodig heeft al te horen krijgt dat ze binnenkort nodig zijn, zodat hij alvast opdacht kan geven om deze klaar te zetten in het cache. Een nadeeltje aan het vervroegd opvragen van gegevens is dat er tussen het halen en daadwerkelijke gebruiken nog iets kan veranderen, daarom checkt de processor vlak voor het uitvoeren van de opdracht nog even of de waarde wel klopt.
Het resultaat dat uiteindelijk uit de compiler komt rollen zijn instructiebundels, waarin een aantal opdrachten zitten waarvan van tevoren is bepaald of ze tegelijkertijd uitgevoerd kunnen worden zonder elkaar te beïnvloeden. Daarnaast is wat extra informatie voor de processor zelf toegevoegd over de opdrachten die in de bundel zitten en het eventuele verband dat ze hebben met de volgende en vorige bundel, omdat ook bundels gegroepeerd worden door de compiler. In een bundel kunnen ook extra opdrachten aanwezig zijn, zoals bijvoorbeeld voor speculation. Dit is een totaal andere manier van werken dan x86, die nog het beste te vergelijken is met de VLIW (Very Long Instruction Word) architectuur die door Transmeta wordt gebruikt.
Intel's Tahoe architectuur
Tahoe, de codenaam van Intel's nieuwe ISA (instruction set architecture) gebaseerd op EPIC heeft als definitieve naam Intel Architecture 64 gekregen. In IA-64 zijn de instructiebundels 128 bit groot en bevatten maximaal drie opdrachten die elk 41 bit groot zijn, dit in tegenstelling tot IA-32, waarin opdrachten geen vaste lengte hebben. Die drie opdrachten nemen samen 123 bit in beslag en dus is er nog 5 bit over voor extra informatie over de instructiegroep, die de processor helpt met het efficiënt gebruiken van zijn beschikbare bronnen.
Naast de grote stap van CISC naar EPIC waagde Intel in haar nieuwe architectuur meteen de sprong van 32 naar 64 bit. Wat wil dat nou precies zeggen? Ten eerste kan de processor met waarden van 64 bit (8 byte) groot werken, dat wil zeggen grotere getallen en nauwkeurigere uitkomsten dan 32 bit processors. Verder kan de adresbus opgerekt worden tot een breedte van 64 bit, waardoor de IA-64 architectuur maximaal 18 Exabyte aan geheugen kan aanspreken. De 4GB die door Windows 98 kan worden gebruikt en zelfs de 64GB die Windows 2000 Datacenter Server in combinatie met Pentium III Xeon processors op dit moment maximaal aankan, vallen daarbij bleek weg.
Verder is in IA-64 software pipelining toegevoegd. Deze feature, die ook wel register rotation heet is vooral handig voor handelingen die herhaald moeten worden op meerdere variabelen, zoals bij while en for loops die bij elke programmeur bekend zijn. In plaats van op een rij van waarden één voor één dezelfde handelingen uit te voeren schuift de processor de waarden in de registers gewoon een plaatsje op. In feite worden de namen van de registers veranderd en wordt de data niet fysiek gekopieerd, maar het effect is hetzelfde: meerdere variabelen in verschillende stadia van de berekeningen zijn tegelijk aanwezig. Dat spaart veel tijd uit omdat de code minder groot is en er minder in het geheugen gekeken hoeft worden.
De hoofdgedachte achter EPIC en IA-64 is parallel werken, een IA-64 processor moet in staat zijn veel dingen tegelijk te doen. Daarvoor zijn niet alleen veel execution units nodig maar ook een hele berg registers. De IA-32 processors die we nu kennen hebben meestal 32 of minder van deze registers, IA-64 processors zullen er daarentegen meer dan 256 nodig hebben. Naast het parallel kunnen werken hebben de vele registers ook nog het voordeel dat complexe berekeningen met veel waarden snel kunnen worden uitgevoerd, zonder steeds terug te vallen op het cache.
De performance van een IA-64 processor is enorm afhankelijk van zijn compiler. Dat is een nadeel, want zo'n compiler is enorm complex om te schrijven, hij moet namelijk met ongelooflijk veel dingen rekening houden om de broncode te analyseren en de instructiebundels samen te stellen. Iemand die zo'n compiler schrijft moet de processor zijn architectuur van binnen en buiten kennen. De compilers voor IA-64 zijn dan ook al bijna even lang in de maak als de architectuur zelf, maar ondanks al die moeite zullen ze bij de release nog niet optimaal zijn. Door optimalisaties en nieuwe ideeën voor slimmere compilers kunnen de prestaties van IA-64 processors in de loop der jaren nog flink stijgen.
De eerste IA-64 hardware...
Nu je weet wat EPIC en IA-64 zijn is het tijd om over de allereerste IA-64 processor te hebben, bij Intel bekend als codename Merced, voor het publiek: Itanium. De fysieke eigenschappen van de Itanium core zijn totaal niet indrukwekkend. Een zes lagen dikke aluminium die met daarop een schamele 25 miljoen transistors gebakken op 0.18 micron, draaiende op een kloksnelheid die niet boven de 800MHz uit komt. Zelfs de Pentium III core lijkt geavanceerder met 28 miljoen transistors en een huidige topsnelheid van 1GHz, laat staan de 42 miljoen transistors tellende 1,5GHz Pentium 4, toch zijn deze cijfers voor een chip die eigenlijk al in 1997 af had moeten zijn lang niet slecht.
Van binnen is de Itanium core dan ook een stuk interessanter, hij is namelijk in staat om twee 128 bit IA-64 instructiebundels tegelijk te verwerken. Dit zijn dus maximaal zes binnenkomen opdrachten per kloktik en omdat sommige opdrachten meerdere operaties vereisen, die door de Itanium tegelijkertijd gedaan kunnen worden, kan het aantal verwerkte operaties per kloktik oplopen tot 20. Daarvoor is dan ook een klein leger execution units en registers ingezet. De 11 execution units en 328 registers kunnen in theorie voor een maximum van 6,4GFLOPS zorgen. Met deze enorme hoeveelheid beschikbare bronnen is het voor de processor mogelijk om parallel te werken zoals dat volgens de EPIC filosofie moet. Hier een overzicht van de interne features:
| | Execution units | | 2 | Floating point units | | 4 | Integer units | | 2 | Load-store units | | 3 | Branch units |
|
| | | Registers | | 128 | Multimedia registers | | 128 | Floating point registers (82 bit) | | 64 | Predicate registers | | 8 | Branch registers |
|
|
De Itanium heeft natuurlijk ook on-die cache, bestaande uit 16KB L1 data, 16KB L1 integer en 96KB L2 cache. Dit lijkt is voor een processor met zulke capaciteiten natuurlijk nogal klein, maar wordt door Intel ruimschoots gecompenseerd door L3 cache te gebruiken. Op de processorcartridge kan 2 of 4MB cache worden geplaatst, dat met een 128 bit brede bus aan de core verbonden wordt. Omdat het cache op de volle processorsnelheid draait wordt de totale bandbreedte naar de processor 11,9GB/s voor de 800MHz versie.
Natuurlijk moest de Itanium ook betrouwbaar zijn, op vrijwel elke interne processorbus is dan ook ECC toegepast, waarmee fouten kunnen worden herkend en hersteld, zonder dat een reboot noodzakelijk is. Fouten kunnen ook worden gelogd en de processor is in staat problemen met de rest van het systeem te herkennen en deze vervolgens te herstellen of in te dammen. De Itanium vertrouwt ook niet meer op het moederbord om zijn voltage stabiel te houden. Aan de zijkant van de zware, grote cartridge waarin de core zit moet een door Intel ontworpen voltage regulator, die nog groter is dan de processor zelf, worden aansloten.
Dan is er nog het probleem van oude software, want hoewel de Itanium een compleet nieuw ontwerp is zullen Intel's klanten zo af en toe ook software willen gebruiken die nog niet gepoort is naar het IA-64 platform. Om die mensen tegemoet te komen zit er op de Itanium een hardware decoder voor IA-32, die 100% compatible is met de huidige software, inclusief MMX en SSE2. Natuurlijk kan de EPIC core niets beginnen met deze opdrachten en dus wordt alles heen en weer vertaald zodat het door de Itanium kan worden uitgevoerd en de resultaten door de oude software worden begrepen.
De chipset waar de Itanium op draait is de Intel 460GX, geschikt voor maximaal vier Itanium processors op een dual-pumped bus van 133MHz (266MHz effectief). De chipset kan maximaal 64GB geheugen aansturen en daarbij kan gekozen worden tussen PC100 SDRAM en PC1600 DDR SDRAM. Een geïntegreerde ethernetkaart en AGP4x zijn optioneel. Voor het grotere werk moet je echter bij andere bedrijven zijn zoals NEC, IBM, HP en Compaq, deze zijn bezig met 16- en 32-way Itanium chipsets. Voor zo'n 32-way systeem zul je overigens je spaarvarken flink moeten uitschudden, een 800MHz Itanium met 4MB L3 cache zal namelijk zo'n 10.000 gulden gaan kosten. Het is nu hopelijk duidelijk dat de Itanium absoluut geen processor voor desktops is  .
.
...en de toekomst
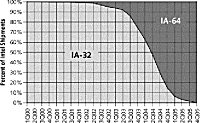
De Itanium is natuurlijk de allereerste IA-64 processor, onder andere ontworpen om software op te ontwikkelen en ervaring op te doen met het ontwerpen van chips die gebruik maken van de nieuwe architectuur. Verder is de Itanium handig om moederborden en chipsets mee te testen. Als je dit bot samen zou vatten zou je kunnen zeggen dat de Itanium niet meer dan een kladje is. Intel zelf lijkt er ook zo over te denken, ze verwachten er slechts enkele tientallen te verkopen, omdat de toepassingen van de processor door de hoge kosten en het gebrek aan software zeer beperkt zullen zijn. Het traject van IA-32 naar IA-64 zal lang zijn en er zijn maar kleine beetjes informatie over beschikbaar.
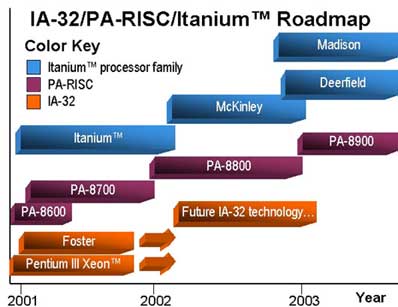
De eerste IA-64 processor die serieuze toepassingen zal krijgen is de McKinley, die in het jaar 2002 de Itanium opvolgt. McKinley zal een pipeline van tien stappen hebben, drie meer dan de Itanium. Daarmee moet bij de release eind dit jaar een kloksnelheid van 1GHz te halen zijn, waarmee hij ongeveer twee keer zo snel moet zijn dan de Itanium. McKinley zal net als Foster, de serverversie van de Pentium 4, gebruik maken van de i870 chipset met ondersteuning voor DDR SDRAM en RDRAM. Tegen die tijd zal er op de Itanium systemen waarschijnlijk genoeg software ontwikkeld zijn, maar of de kosten zakken is te betwijfelen. De yields zullen namelijk niet veel beter worden omdat Intel 4MB L3 cache, bestaande uit bijna 300 miljoen transistors, op de chip wil integreren.
Om de kosten te drukken wil Intel overstappen naar het goedkopere 0.13 micron productieproces en eind 2002 zal de eerste IA-64 processor deze stap nemen. Deze chip heeft de codenaam Madison en is de opvolger van McKinley. De kleinere die-size is echter niet de enige belangrijke ontwikkeling die in die tijd zal plaatsvinden, Intel wil dan namelijk in de buurt van mid-end servers/high-end workstations komen door een goedkopere versie van Madison te releasen. Deze processor, waarvan we alleen de codenaam Deerfield kennen, zal lang niet zo snel zijn, maar wel een prijskaartje hebben dat een stuk interessanter is.
De concurrentie:
 Als kleine zijnoot in dit artikel even een stukje over x86-64, AMD's antwoord op IA-64. Beide architecturen zijn 64 bit, maar in tegenstelling tot Intel heeft AMD niet de moeite genomen om een compleet nieuw ontwerp te maken. In plaats daarvan is simpelweg hun bestaande architectuur uitgebreid met een aantal 64 bit trucjes. De eerste x86-64 processor zal de Sledgehammer zijn, die begin 2002 op de markt moet komen. Met de Clawhammer, een goedkopere versie van de Sledgehammer, richt AMD zich meteen bij de release van de architectuur op de consument. Het voordeel van AMD's aanpak is dat ze een stuk minder geld kwijt zijn en veel betere ondersteuning voor bestaande software hebben, maar het nadeel is dat de technologie nog steeds gebaseerd is op het snel verouderende x86.
Als kleine zijnoot in dit artikel even een stukje over x86-64, AMD's antwoord op IA-64. Beide architecturen zijn 64 bit, maar in tegenstelling tot Intel heeft AMD niet de moeite genomen om een compleet nieuw ontwerp te maken. In plaats daarvan is simpelweg hun bestaande architectuur uitgebreid met een aantal 64 bit trucjes. De eerste x86-64 processor zal de Sledgehammer zijn, die begin 2002 op de markt moet komen. Met de Clawhammer, een goedkopere versie van de Sledgehammer, richt AMD zich meteen bij de release van de architectuur op de consument. Het voordeel van AMD's aanpak is dat ze een stuk minder geld kwijt zijn en veel betere ondersteuning voor bestaande software hebben, maar het nadeel is dat de technologie nog steeds gebaseerd is op het snel verouderende x86.
Het testen van de Itanium
Toen we hoorden dat we de Itanium mochten previewen waren we natuurlijk blij, maar al snel rezen een aantal belangrijke vragen in ons op. We waren namelijk zo'n beetje de eersten die dit mochten doen en hadden dus geen flauw idee hoe we dit het beste konden aanpakken. Na intensieve speurtochten over de hele wereld, van vage Japanse sites naar Intel's Developer forum en mailtjes naar een aantal grote namen als Paul DeMone bleek dat er nog geen enkele stukje IA-64 software voor Windows te vinden was. Intel's V-Tune 5.0 compiler met ondersteuning voor Itanium en Pentium 4 was slechts aan een zeer select groepje mensen uitgegeven en beta-versies van Microsoft SQL Server 64 lagen ook niet bepaald voor het oprapen. Er zijn natuurlijk wel IA-64 Linux distributies te downloaden, maar omdat het systeem al Windows Whistler draaide zou dat een beetje lastig worden.
Het advies wat we dat ook kregen was om ons te richten op x86 performance, omdat -zeker in het begin- IA-64 software schaars zal zijn is dat bijna even belangrijk als de prestaties in IA-64 mode. De benchmarks die we meenamen zijn zullen je dan ook grotendeels bekend voorkomen. Aan de ene kant is dat natuurlijk wel leuk, omdat je op die manier veel vergelijkingsmateriaal hebt, maar van de andere kant is het natuurlijk jammer dat we geen echt beeld konden krijgen van hetgeen waar de Itanium voor bedoeld is: IA-64.
Het door ons geteste systeem had de volgende configuratie:
| | Testsysteem | | Processor | Intel Itanium 667MHz | | Moederbord | Intel 460GX chipset, dual Socket M | | Geheugen | 512MB PC100 SDRAM | | Videokaart | ATi Rage 128 | | Opslag | 2x 18GB Ultra160 SCSI | | Software | Whistler Advanced Server 64 bit (Beta 1, Build 2296) |
|
Helaas mochten we geen foto's maken van het systeem omdat aan de hand van het ontwerp en de overal aanwezige serienummers de eigenaar makkelijk achterhaald zou kunnen worden, waardoor deze in de problemen zou komen. Ik kan wel vertellen dat het systeem in één woord lomp is. Er zijn twee sterke mannen nodig om de kast op te tillen en de gemiddelde stofzuiger komt niet boven de herrie uit die het ding veroorzaakte en dat is geen grap. Al met al erg indrukwekkend dus, maar jullie willen natuurlijk benchmarks zien.
Whistler wilde echter niet echt meewerken, of dat nu aan het operating systeem zelf lag of aan de exotische Itanium hardware is niet bekend, maar veel van de standaard benchmark pakketten wilden niet werken. SiSoft Sandra 2001 weigerde te installeren, SysMark 2000 en WinBench99 precies hetzelfde verhaal. 3DMark 2000 en Quake3 weigerden ook, omdat de videokaart niet DirectX 7 compatible was. Daar zaten we dan, een berg software om de beperkte tijd die we hadden nuttig te gebruiken, maar meteen zo'n tegenwerking van het systeem  . We konden niet eens een WCPUID screenshot maken, daarom zullen jullie het hiermee moeten doen:
. We konden niet eens een WCPUID screenshot maken, daarom zullen jullie het hiermee moeten doen:
Benchmarks: Rc5, Chess & Stream
Gelukkig zijn er meer benchmarks dan alleen degenen die je overal ziet. Zo is er bijvoorbeeld de Distributed.net client, beter bekend als 'de koe'. Deze bleek gelukkig wel te werken op het systeem, hoewel de processor uiteraard niet werd herkend. Na de automatische selectie van de snelste core startten we vol goede moed een benchmark... Een paar seconden lagen onze kaken op de grond, want de Itanium haalde nog geen 96 kkeys/s, een score die zelfs door 486 verbeterd kan worden! De Rc5 cores van de client zijn natuurlijk zwaar geoptimaliseerd voor echte x86 processors, waardoor een goede score eigenlijk al uitgesloten was, maar zó slecht had waarschijnlijk niemand verwacht:
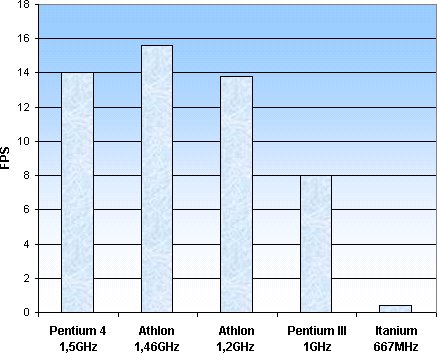
Als tweede test hebben we Tom Kerrigan's Simple Chess Program, een klein programmaatje speciaal geschreven om de branch predictors van de processor tot het uiterste te belasten. Dit doet het tooltje door een simulatie van een schaakwedstrijd te doen. Na een aantal zetten drie keer te berekenen komt de gemiddelde snelheid van de processor in MIPS naar buiten. De EPIC hardware is in theorie in staat om juist met dit soort dingen beter te presteren dan IA-32 processors, maar de x86 - IA-64 converter bleek zijn werk niet goed te doen. De score van de Itanium was namelijk ook hier om te huilen, zelfs de Pentium 100 wist de 64 bit titaan voorbij te snellen, om maar niet te spreken over de 20 maal snellere Pentium 4:
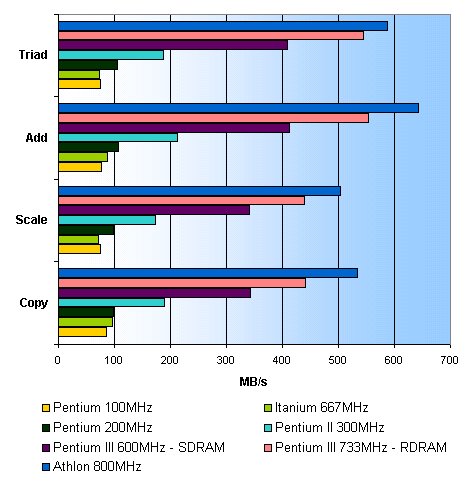
Voor we overgaan naar meer real-life benchmarks hebben we nog één synthetische, namelijk Stream, een programma dat de geheugenbandbreedte tijdens verschillende operaties meet. Of het nu aan het moederbord lag of aan de processor zelf, de Itanium bleek qua bandbreedte in verhouding al een stuk sneller te zijn. In plaats van rond het niveau van de Pentium 75 te zweven kwam hij hier namelijk al in de buurt van de Pentium 200  :
:
Benchmarks: FlaskMPEG & TestCPU
De Itanium doet het tot nu toe niet goed, maar er is nog hoop, wellicht is hij wel in staat om x86 floating point berekeningen snel te doen. Om naar dat punt te kijken zullen we resultaten van FlaskMPEG gebruiken. Flask is een programma om videobeelden te comprimeren en dat is zoals je wel kunt vermoeden zwaar floating point werk. Als invoer is een .vob file, geript van de DVD van de film 'The Matrix' gebruikt. Verder was Tom's Hardware zo vriendelijk om wat vergelijkingsmateriaal te leveren. Om het eerlijk te houden zijn daarom dezelfde instellingen gebruikt:
| | FlaskMPEG setup | | Codec | DivX 3.11 alpha, Fast-Motion | | Resolutie | 720 x 480, 29.97 FPS | | Data rate | 910 kbps, keyframe om de 10 seconden | | Audio | Niet verwerkt |
|
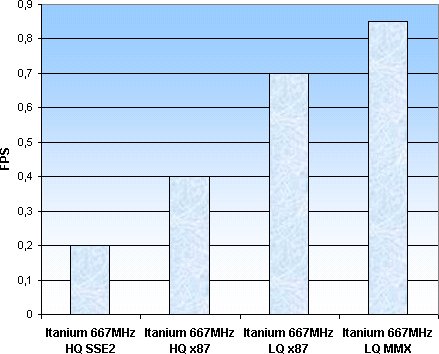
High Quality, x87 optimized:
High Quality, SSE2/3DNow! optimized:
Itanium scores vergeleken:
Commentaar geven is haast overbodig, want het is overduidelijk dat de Itanium een enorme achterstand heeft. Alleen uit de laatste grafiek kan men een aantal dingen opmerken, zo blijkt dat SSE2 emulatie op de Itanium dingen alleen nog maar erger maakt. Dat is vreemd want op de Pentium 4 leveren deze 144 extra instructies een flinke snelheidswinst op. Een verklaring hiervoor zou kunnen zijn dat de vertaalhardware moeite heeft met de 'speciale' instructies die in IA-32 zitten, maar dat klopt niet omdat het gebruik van MMX wél een redelijke procentuele winst oplevert. Verder heeft de Itanium naast de mogelijkheid om SSE2 te vertalen ook de mogelijkheid om native IA-64 SSE2 instructies te verwerken, het vertalen zou daarom geen probleem moeten zijn.
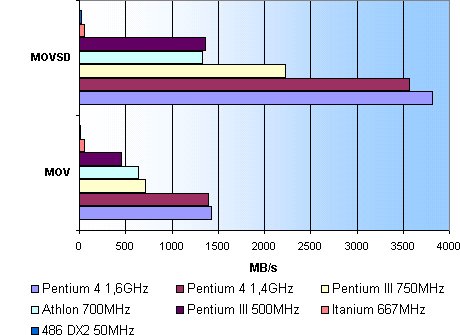
Als laatste benchmark hebben we het programma TestCPU, een veelzijdige test van zo'n beetje alle aspecten van de CPU:
Conclusie
Voor je nu hieronder je reactie begint te tikken met 'Intel sucks ' is het aan te raden om dit laatste stuk ook nog even door te lezen. Er zijn namelijk een aantal punten waarmee de slechte performance in onze benchmarks kan worden goedgepraat.
Pre-release hardware:
De Itanium die door ons getest is was zoals je weet een 667MHz model. De versies die gereleased worden zullen op 733 en 800MHz draaien. Die extra kloksnelheid op zich wil natuurlijk niet zeggen dat de Itanium ineens een stuk sneller zal zijn, maar we moeten er rekening mee houden dat de final versie van de hardware ook nog andere veranderingen kan ondergaan, zoals een snellere revisie van de core of een betere IA-32 decoder. Het is niet erg waarschijnlijk dat de performance ineens extreem vooruit gaat, maar het zou geen verrassing zijn als hij nog verbeterd wordt.
Pre-release software:
Windows Whistler zelf is nog in Beta, maar ook de IA-64 HAL (Hardware Abstraction Layer) is waarschijnlijk nog verre van af. Microsoft zal voor de release van het 64 bit operating systeem nog veel dingen verbeteren en optimaliseren, wat uiteraard ook in betere performance resulteert. We weten immers niet in hoeverre de hardware verantwoordelijk was voor de traagheid, voor hetzelfde geld ligt het probleem bij de software.
Gebrek aan IA-64 benchmarks:
We waren niet in staat om IA-64 software te draaien op het systeem omdat die simpelweg nergens te vinden was. Je moet er rekening mee houden dat de Itanium 100% is ontworpen voor IA-64 code en dat de IA-32 decoder maar een bijzaak was voor Intel. De ware kracht van de processor ligt dan ook niet in de tests die wij gedaan hebben maar in de applicaties die nog in ontwikkeling zijn. Vroege benchmarks van IA-64 code op Itanium systemen hebben echter al uitgewezen dat de nieuwe architectuur zeker in staat is om de Pentium 4 het veld uit te blazen met de helft van de kloksnelheid.
Uit eigen ervaring kunnen we alleen spreken over Whistler, de enige stuk Itanium software dat we hebben kunnen bekijken. Het operating system liep soepel, waardoor we in ieder geval kunnen concluderen dat de Itanium in IA-64 mode minstens even snel is als een normale Pentium III of Athlon processor met een gelijke kloksnelheid.
Itanium als onderdeel van het grote geheel:
De Itanium mag dan nog geen ideale performance hebben en al helemaal geen prijs/prestatieverhouding, maar dat is ook helemaal nooit Intels bedoeling geweest. De eerste IA-64 processor is gemaakt om te bewijzen dat het mogelijk is en om er software op te ontwikkelen. De Itanium is niet meer dan een opstapje voor de tweede generatie McKinley, die ook zijn levensdagen zal moeten slijten in extreem dure databaseclusters. Pas over 3 à 4 jaar zullen de opvolgers van de Itanium je huiskamer binnenkomen en dat is genoeg tijd om de IA-32 prestaties te verbeteren. De introductie van de nieuwe 64 bit EPIC architectuur is zonder twijfel het grootste en langstlopende Intel project ooit en de Itanium is slechts een opstapje voor wat ons de komende 25 jaar te wachten staat.
Slotwoord:
De IA-64 architectuur is veelbelovend door de revolutionaire EPIC features, die het in de toekomst mogelijk gaan maken om krachtigere computers te bouwen dan ooit tevoren. Er is echter een lange weg te gaan en voor je afknapt op de slechte IA-32 performance van de eerste chip moet je eerst naar het grote geheel kijken. Dit zul je namelijk voorlopig niet thuis zien:
Finally, we would like to thank the person who made this review possible, his name has to be kept secret, but we know who you are!
English visitors: You might want to check out the translation .



















:strip_icc():strip_exif()/u/2626/nice_eye.jpg?f=community)
/u/8/oog3.png?f=community)
:strip_exif()/u/1165/thunk.gif?f=community)
:strip_exif()/u/818/we33ee45.gif?f=community)
:strip_exif()/u/5079/tweak.gif?f=community)
:strip_icc():strip_exif()/u/5632/crop60183aa7687b6_cropped.jpeg?f=community)
/u/12038/crop69547035714ff_cropped.png?f=community)
:strip_icc():strip_exif()/u/2189/baby.jpg?f=community)
:strip_exif()/u/14699/initial.gif?f=community)
:strip_icc():strip_exif()/u/484/crop651fd77412597_cropped.jpg?f=community)
/u/9354/imagesmall.png?f=community)
:strip_icc():strip_exif()/u/218/em.jpg?f=community)
:strip_exif()/u/575/output_4QII01.gif?f=community)
:strip_exif()/u/8422/waarschuwing.gif?f=community)